Factorial designs are widely used in experiments involving several factors where it is necessary to study the joint effect of the factors on a response.
Chapter 5 presented general methods for the analysis of factorial designs.
However, several special cases of the general factorial design are important because they are widely used in research work and also because they form the basis of other designs of considerable practical value.
The most important of these special cases is that of \(k\) factors, each at only two levels.
These levels may be quantitative, such as two values of temperature, pressure, or time; or they may be qualitative, such as two machines, two operators, the “high” and “low” levels of a factor, or perhaps the presence and absence of a factor.
A complete replicate of such a design requires \(2\times 2\times \cdots \times 2=2^k\) observations and is called a \(2^k\) factorial design.
This chapter focuses on this extremely important class of designs. Throughout this chapter, we assume that
the factors are fixed,
the designs are completely randomized, and
the usual normality assumptions are satisfied.
The \(2^k\) design is particularly useful in the early stages of experimental work when many factors are likely to be investigated.
It provides the smallest number of runs with which \(k\) factors can be studied in a complete factorial design.
Consequently, these designs are widely used in factor screening experiments (where the experiments is intended in discovering the set of active factors from a large group of factors).
6.2 The \(2^2\) design
The first design in the \(2^k\) series is one with only two factors, say \(A\) and \(B\), each run at two levels.
This design is called a \(2^2\) factorial design.
The levels of the factors may be arbitrarily called “low” and “high.”
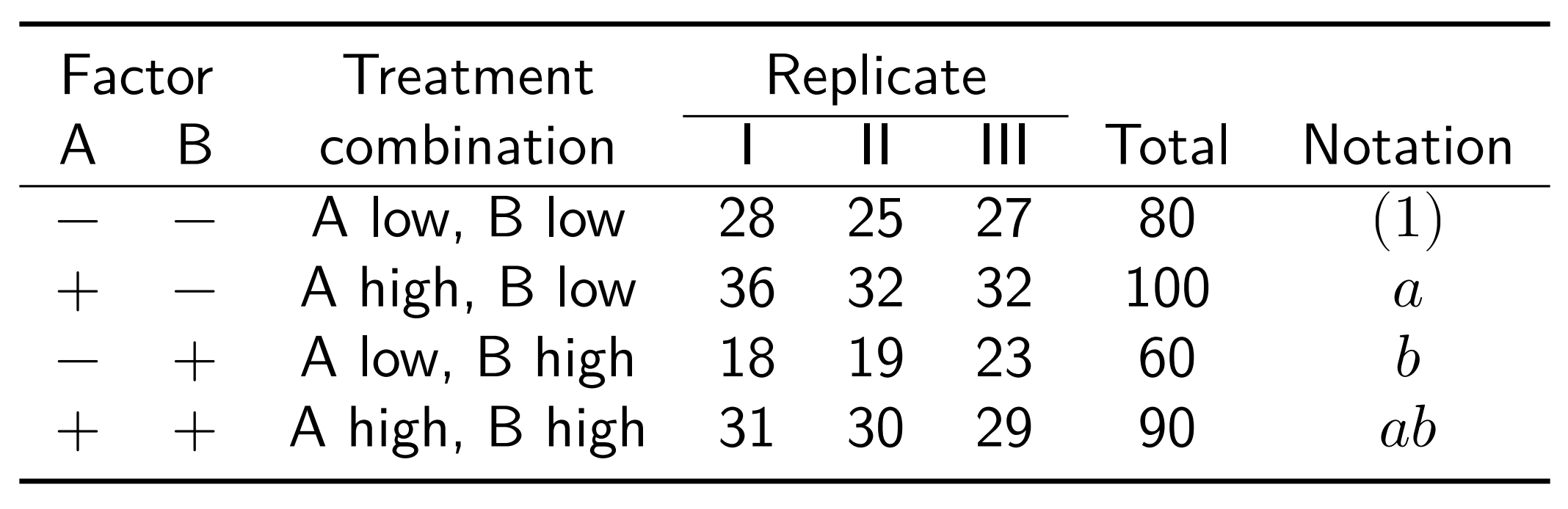
Consider an investigation into the effect of the concentration of the reactant (factor A) and the amount of catalyst (factor B) on the yield in a chemical process.
Levels of factor A: 15 and 25 percent
Levels of factor B: 1 and 2 pounds
The objective of the experiment is to determine if adjustments to either of these two factors would increase the yield.
The experiment is replicated three times, so there are 12 runs. The order in which the runs are made is random, so this is a completely randomized experiment.
Data layout:
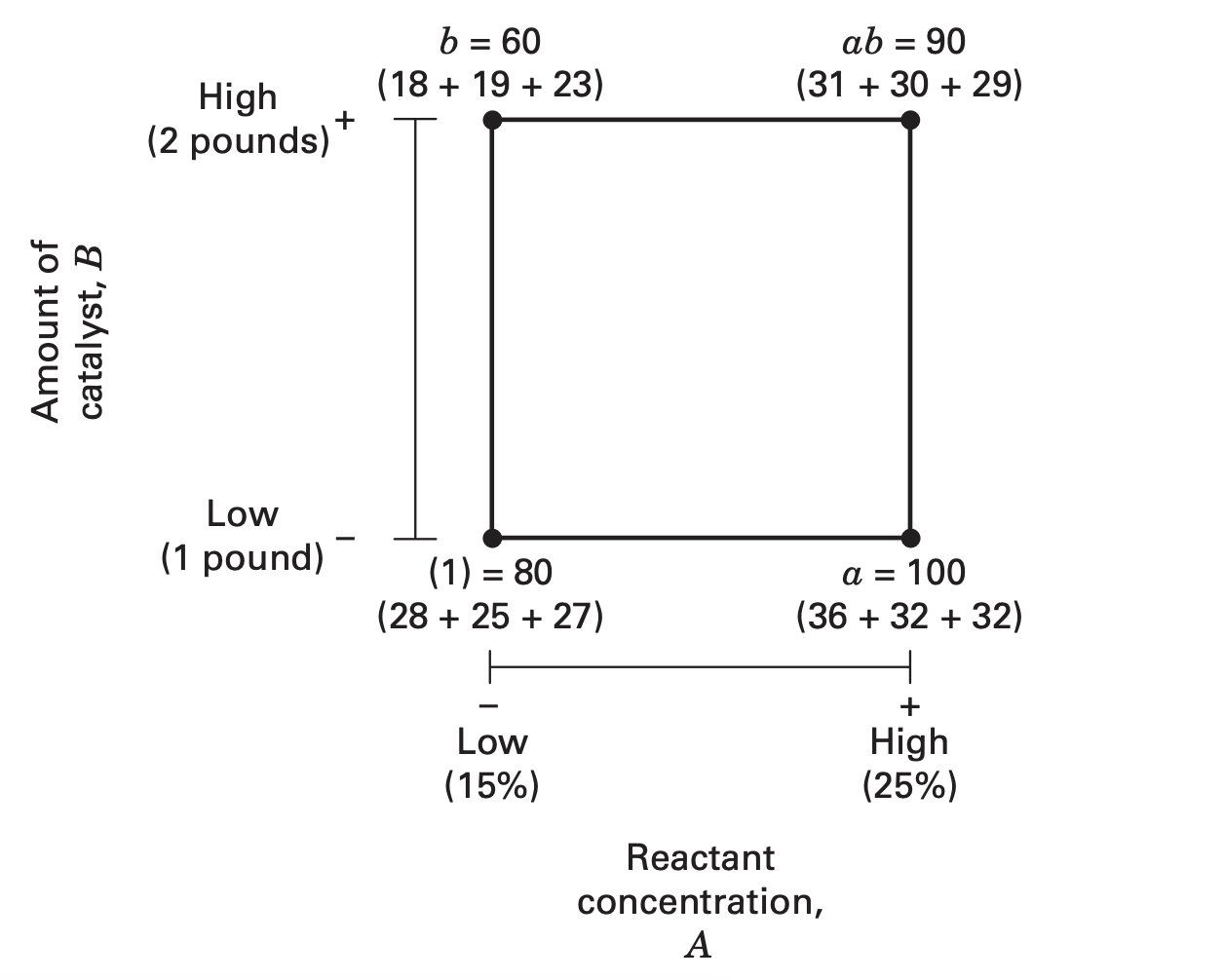
Graphical view:
By convention, we denote the effect of a factor by a capital Latin letter.
“A” refers to the effect of factor A,
“B” refers to the effect of factor B, and
“AB” refers to the AB interaction.
The four treatment combinations in the design are represented by lowercase letters.
The high level of any factor in the treatment combination is denoted by the corresponding lowercase letter and that the low level of a factor in the treatment combination is denoted by the absence of the corresponding letter.
Thus \({\color{blue} a}\) represents the treatment combination of \(A\) at the high level and \(B\) at the low level, \({\color{blue} b}\) represents \(A\) at the low level and \(B\) at the high level, and \({\color{blue} ab}\) represents both factors at the high level.
By convention, (1) is used to denote both factors at the low level.
This notation is used throughout the \(2^ k\) series.
In a two-level factorial design the average effect of a factor is defined as the change in response produced by a change in the level of that factor averaged over the levels of the other factor.
The symbols (1), \(a\), \(b\), and \(ab\) represent the total of the response observation at all \(n\) replicates taken at the treatment combination.
The effect of \(A\) at the low level of B is \([a - (1)]/n\), and the effect of \(A\) at the high level of \(B\) is \([ab - b]/n\). Averaging these two quantities yields the main effect of \(A\): \[
\begin{aligned}
A &=\frac{1}{2} \bigg\{ \frac{[a b-b]+[a-(1)]}{n}\bigg\} \\
&=\frac{1}{2 n}[a b+a-b-(1)]
\end{aligned}
\]
The main effect of \(B\) is: \[
\begin{aligned}
B &=\frac{1}{2} \bigg\{ \frac{[a b-a]+[b-(1)]}{n}\bigg\} \\
&=\frac{1}{2 n}[a b+b-a-(1)]
\end{aligned}
\]
We define the interaction effect\(A B\) as the average difference between the effect of \(A\) at the high level of \(B\) and the effect of \(A\) at the low level of \(B\). Thus, \[
\begin{aligned}
A B &=\frac{1}{2} \bigg\{ \frac{[a b-b]-[a-(1)]}{n}\bigg\} \\
&=\frac{1}{2 n}[a b+(1)-a-b] \qquad \qquad \qquad (6.3)
\end{aligned}
\]
Alternatively, we may define \(AB\) as the average difference between the effect of \(B\) at the high level of A and the effect of \(B\) at the low level of A. This will also lead to Equation 6.3.
\[
\begin{aligned}
A &=\frac{1}{2(3)}(90+100-60-80)=8.33 \\
B &=\frac{1}{2(3)}(90+60-100-80)=-5.00 \\
A B &=\frac{1}{2(3)}(90+80-100-60)=1.67
\end{aligned}
\]
The effect of A (reactant concentration) is positive; this suggests that increasing A from the low level \((15\%)\) to the high level \((25\%)\) will increase the yield.
The effect of B (catalyst) is negative; this suggests that increasing the amount of catalyst added to the process will decrease the yield.
The interaction effect appears to be small relative to the two main effects.
The magnitude and direction of factor effects can be used to determine the important factor and ANOVA can generally be used to confirm the interpretation.*
Sum of squares
Now we consider determining the sums of squares for \(A\), \(B\), and \(AB\).
Note that, in estimating A, a contrast is used: \[\begin{align*}
A = \frac{1}{2n}[ab + a -b -(1)] = \Big(\frac{1}{2n}\Big)\;\; \text{Contrast}_A
\end{align*}\] Similarly, \[\begin{align*}
B &= \frac{1}{2n}[ab - a +b -(1)] = \Big(\frac{1}{2n}\Big)\;\; \text{Contrast}_B \\ ~ \\
AB &= \frac{1}{2n}[ab - a - b +(1)] = \Big(\frac{1}{2n}\Big)\;\; \text{Contrast}_{AB}
\end{align*}\]
The three contrasts — \(\text{Contrast}_A\), \(\text{Contrast}_B\), and \(\text{Contrast}_{AB}\) — are orthogonal.
The sum of squares for any contrast is equal to the contrast squared divided by the number of observations in each total in the contrast times the sum of the squares of the contrast coefficients. \[
SS_A = \Big(\frac{1}{2^2 n}\Big) \text{Contrast}_A^2=\frac{1}{4n}\,[ab + a -b - (1)]^2
\]
\[\begin{align*}
SS_A &= \Big(\frac{1}{2^2 n}\Big) \text{Contrast}_A^2=\frac{1}{4n}\,[ab + a -b - (1)]^2 \\~\\
SS_B &= \Big(\frac{1}{2^2 n}\Big) \text{Contrast}_B^2=\frac{1}{4n}\,[ab - a + b - (1)]^2 \\~\\
SS_{AB} &= \Big(\frac{1}{2^2 n}\Big) \text{Contrast}_{AB}^2=\frac{1}{4n}\,[ab - a - b + (1)]^2
\end{align*}\] Total sum of squares \[\begin{align*}
SS_T &= \sum_i \sum_j \sum_k y_{ijk}^2 - \frac{y_{\cdot\cdot\cdot}^2}{4n}
\end{align*}\] Error sum of square \[\begin{align*}
SS_E &= SS_T - SS_A - SS_B - SS_{AB}
\end{align*}\]
\[\begin{align*}
SS_A &= \Big(\frac{1}{2^2 n}\Big) \text{Contrast}_A^2=\frac{1}{4n}\,[ab + a -b - (1)]^2 ={\color{red}208.333} \\~\\
SS_B &= \Big(\frac{1}{2^2 n}\Big) \text{Contrast}_B^2=\frac{1}{4n}\,[ab - a + b - (1)]^2 ={\color{red}75}\\~\\
SS_{AB} &= \Big(\frac{1}{2^2 n}\Big) \text{Contrast}_{AB}^2=\frac{1}{4n}\,[ab - a - b + (1)]^2 ={\color{red}8.333}
\end{align*}\] Total sum of squares \[\begin{align*}
SS_T &= \sum_i \sum_j \sum_k y_{ijk}^2 - \frac{y_{\cdot\cdot\cdot}^2}{4n}={\color{red} 323}
\end{align*}\] Error sum of square \[\begin{align*}
SS_E &= SS_T - SS_A - SS_B - SS_{AB} = {\color{red}31.333}
\end{align*}\]
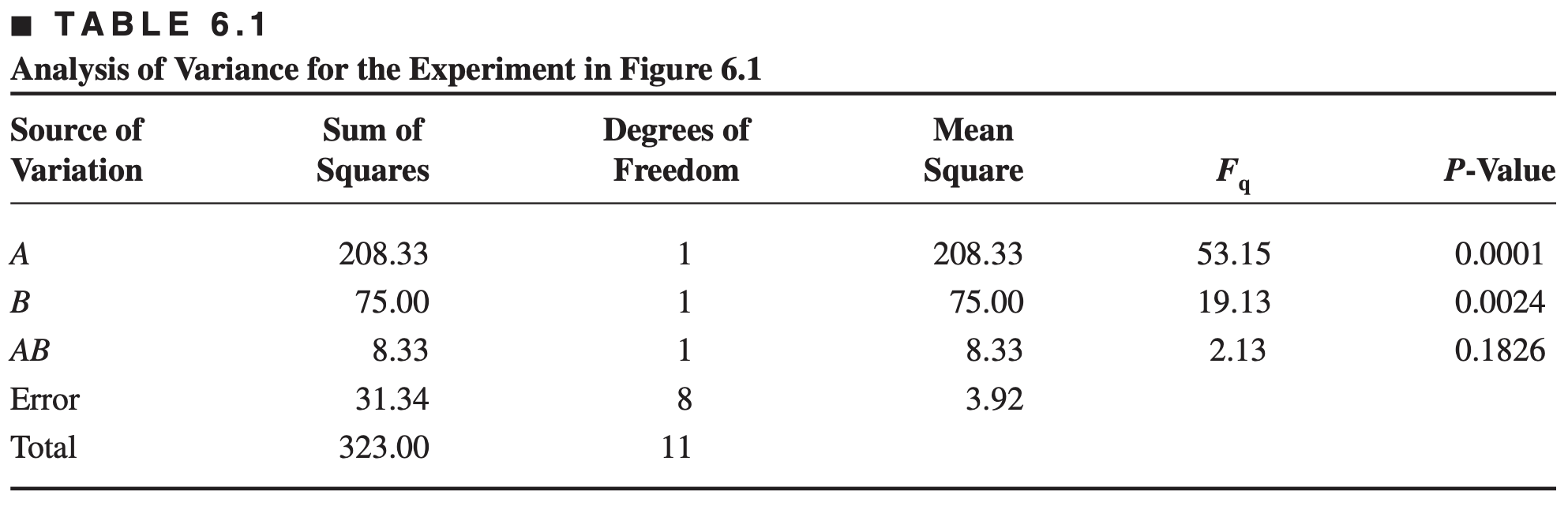
Analysis of Variance table
On the basis of the p-values, we conclude that the main effects are statistically significant and that there is no interaction between these factors. This confirms our initial interpretation of the data based on the magnitudes of the factor effects.
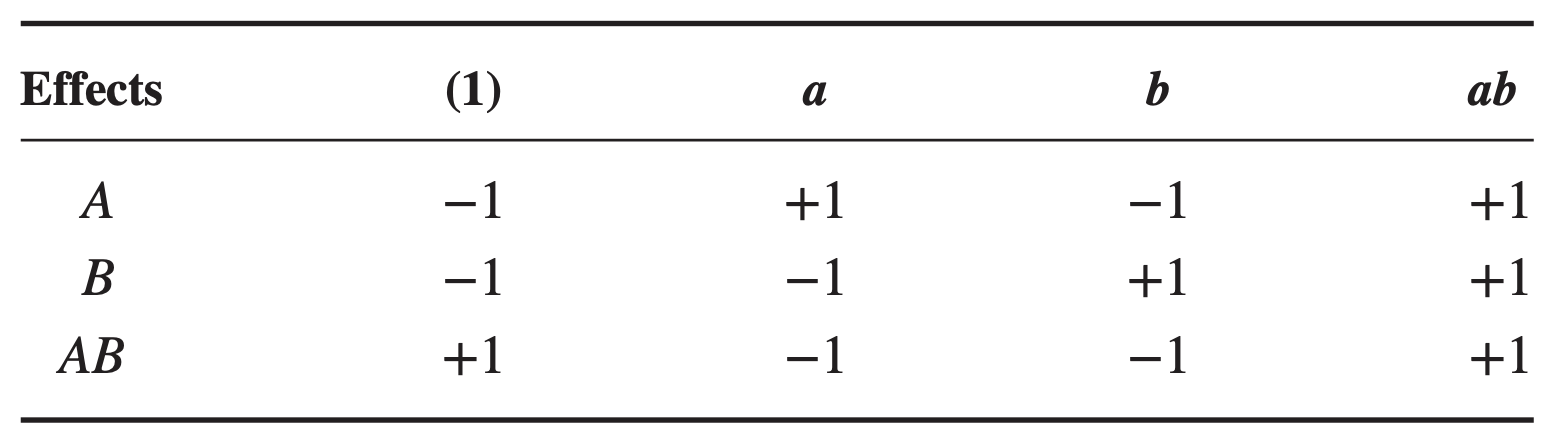
Standard order of treatment combinations
Treatment combinations written in the order \((1), a, b, ab\) is known as standard order or Yates’ order.
Using this standard order, we see that the contrast coefficients used in estimating the effects are
Note that the contrast coefficients for estimating the interaction effect are just the product of the corresponding coefficients for the two main effects.
Algebraic signs for calculating effects in \(2^2\) design
The contrast coefficient is always either +1 or −1, and a table of plus and minus signs such as in Table 6.2 can be used to determine the proper sign for each treatment combination
The symbol “I” indicates the total or average of the entire experiment.
To find the contrast for estimating any effect, simply multiply the signs in the appropriate column of the table by the corresponding treatment combination and add.
For example, to estimate \(A\), the contrast is \(-(1) + a - b + ab.\)
The contrasts for the effects \(A, B\), and \(A B\) are orthogonal. Thus, the \(2^2\) (and all \(2^{\mathrm{k}}\) designs) is an orthogonal design.
The \(\pm 1\) coding for the low and high levels of the factors is often called the orthogonal coding or the effects coding.
Regression model
In a \(2^k\) factorial design, it is easy to express the results of the experiment in terms of a regression model.
For the chemical process experiment, the regression model is \[\begin{align*}
y &= \beta_0 + \beta_1 x_{1} + \beta_2 x_{2} + \epsilon,
\end{align*}\] where
\(x_1\) and \(x_{2}\) are the coded variables for the reactant concentration and the amount of catalyst, respectively
\(\beta\)’s are regression coefficients
The relationship between the natural variables, the reactant concentration and the amount of catalyst, and the coded variables is \[\begin{align*}
x_1 & = \frac{\text{Conc} - (\text{Conc}_{\text{low}} + \text{Conc}_{\text{high}})/2}{(\text{Conc}_{\text{high}} - \text{Conc}_{\text{low}})/2} \\~\\
x_2 & = \frac{\text{Catalyst} - (\text{Catalyst}_{\text{low}} + \text{Catalyst}_{\text{high}})/2}{(\text{Catalyst}_{\text{high}} - \text{Catalyst}_{\text{low}})/2} \\~\\
\end{align*}\]
# Define the datay <-c(28, 25, 27, 36, 32, 32, 18, 19, 23, 31, 30, 29)A <-rep(c(15, 25), each =3, times =2)B <-rep(c(1, 2), each =6)# Create the data frame and compute coded variablesdat <-data.frame(A = A, B = B, y = y) |>transform(A_coded = (A -mean(A)) /abs(diff(range(A)) /2),B_coded = (B -mean(B)) /abs(diff(range(B)) /2) )print(head(dat))
The regression model \[\begin{align*}
\hat{y} &= 27.5 + \Big(\frac{8.33}{2}\Big) x_{1} + \Big(\frac{-5.00}{2}\Big) x_{2}
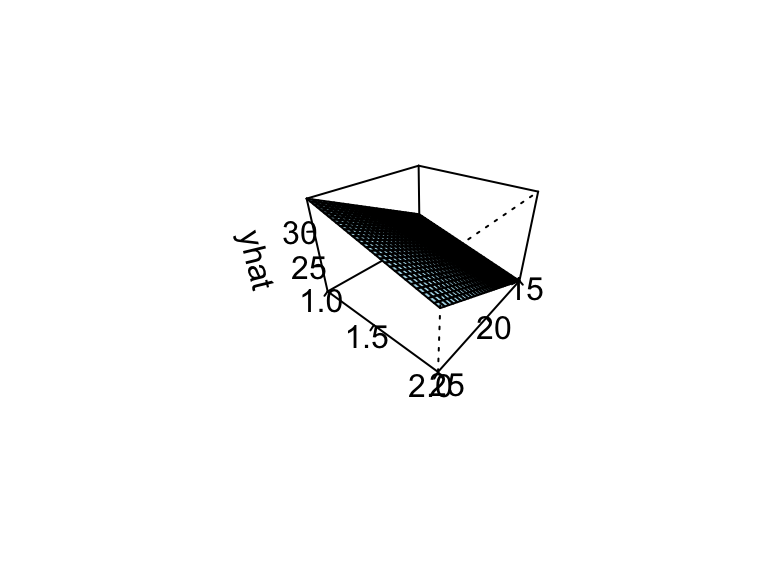
\end{align*}\] can be used generate response surface plots.
It is desirable to construct such plots on the natural factor levels than the coded factor levels, so \[\begin{align*}
\hat{y} &= 27.5 + \Big(\frac{8.33}{2}\Big) \Big(\frac{\text{Conc}-20}{5}\Big) + \Big(\frac{-5.00}{2}\Big) \Big(\frac{\text{Catalyst}-1.5}{0.5}\Big) \\
&= 18.33 + 0.833\, \text{Conc} -5.00\, \text{Catalyst}
\end{align*}\]
res <-lm(y~A+B, data=dat)res
Call:
lm(formula = y ~ A + B, data = dat)
Coefficients:
(Intercept) A B
18.3333 0.8333 -5.0000
A router is used to cut registration notches in printed circuit boards. The average notch dimension is satisfactory, but there is too much variability in the process. This excess variability leads to problems in board assembly. A quality control team assigned to this project decided to use a designed experiment to study the process. The team considered two factors: bit size (\(A\)) and speed (\(B\)).
Two levels were chosen for each factor (bit size \(A\) at 1/16 inch and 1/8 inch and speed \(B\) at 40 rpm and 80 rpm and a \(2^2\) design was set up. Four boards were tested at each of the four runs in the experiment, and the resulting data are shown in the following table:
Compute the sum of squares associated with the effects.
Construct the ANOVA table and draw conclusion.
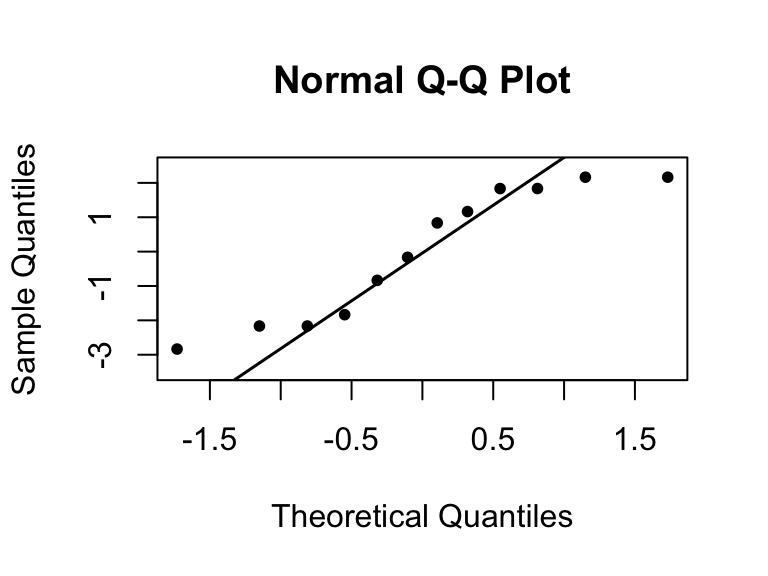
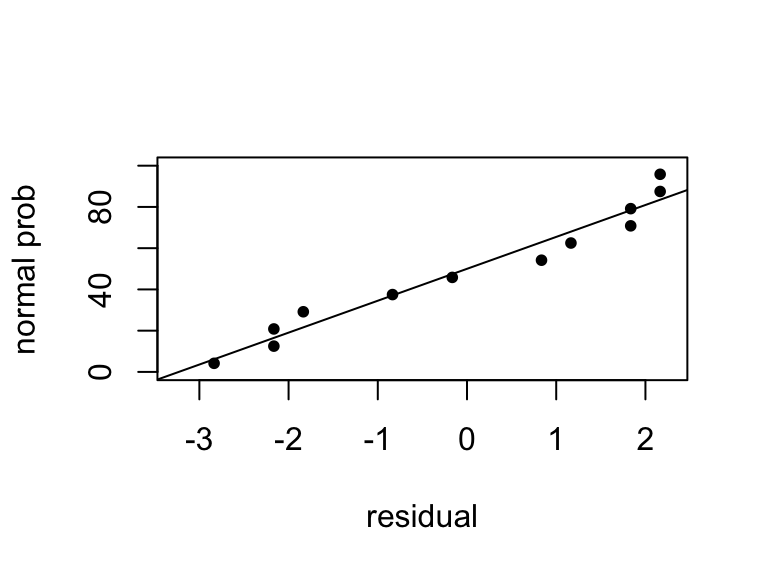
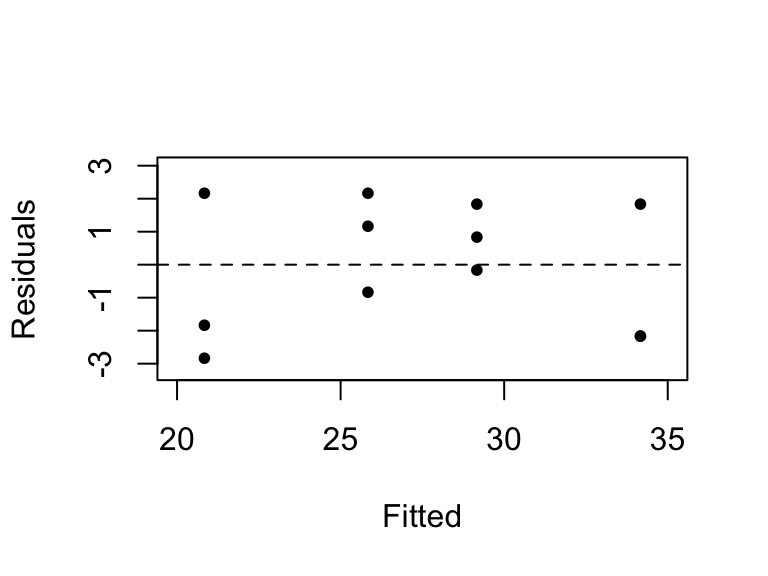
Find residuals using regression method.
6.3 The \(2^3\) design
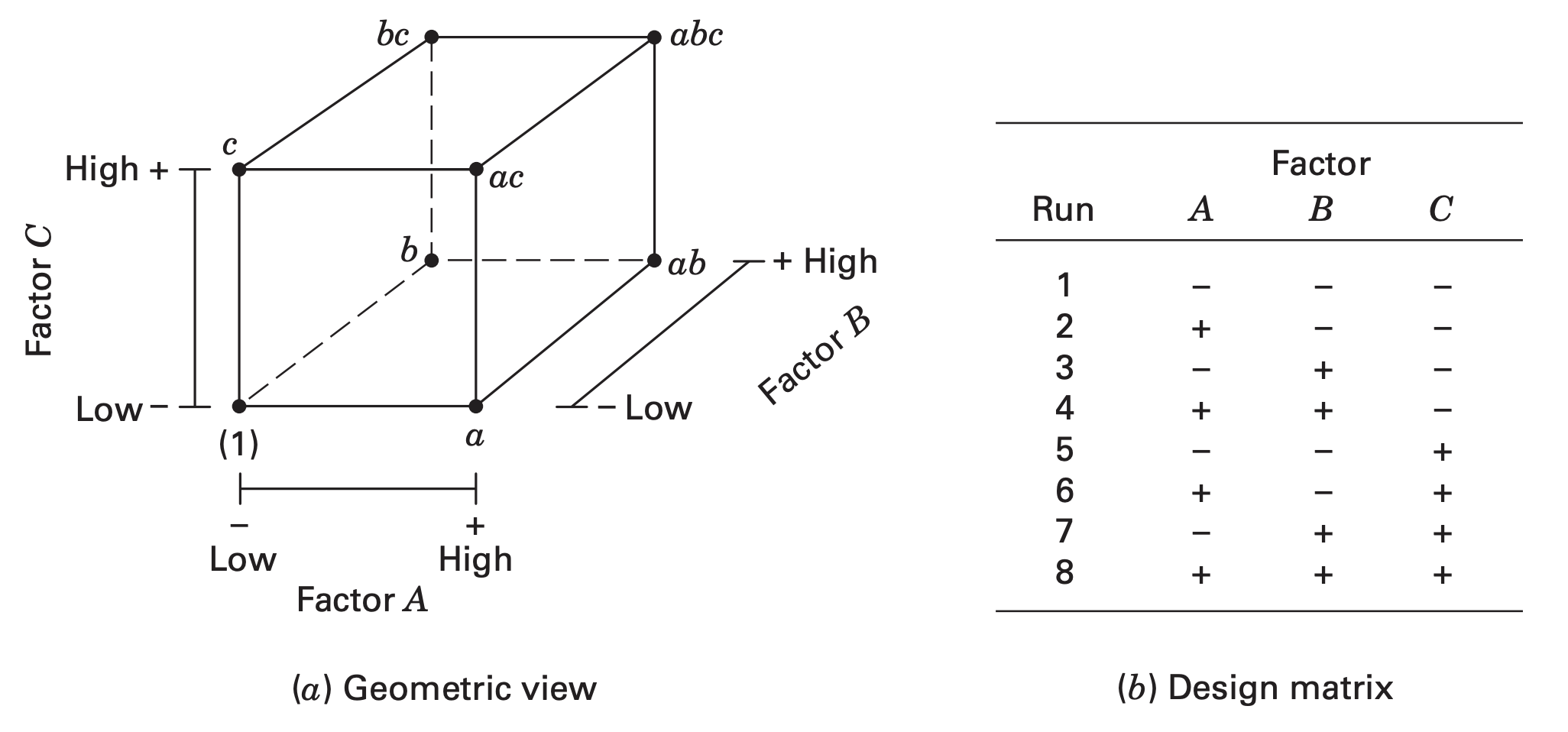
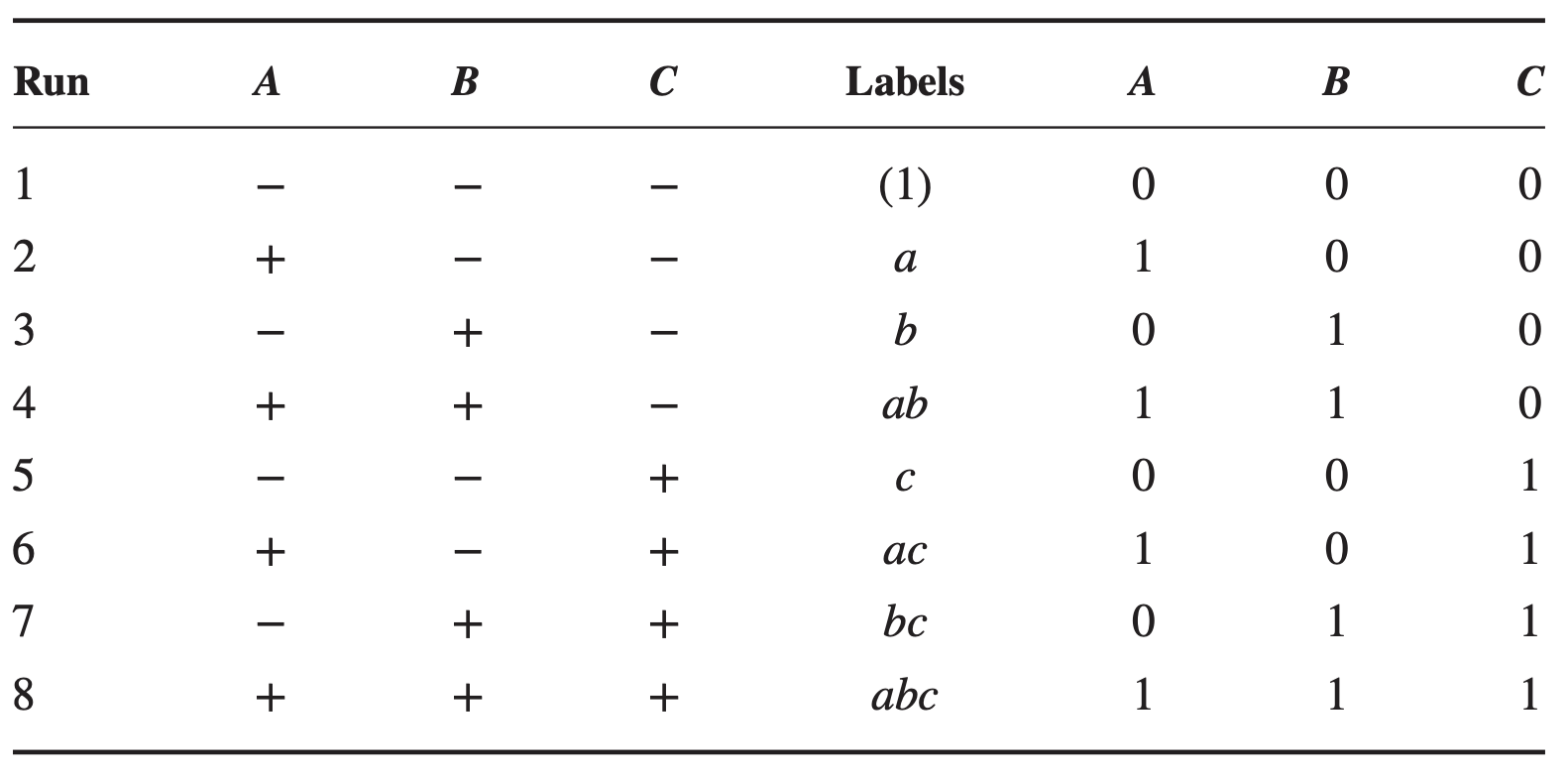
The \(2^3\) factorial design has three factors (say \(A\), \(B\), and \(C\)) and each factor has two levels each. The design has 8 treatment combinations.
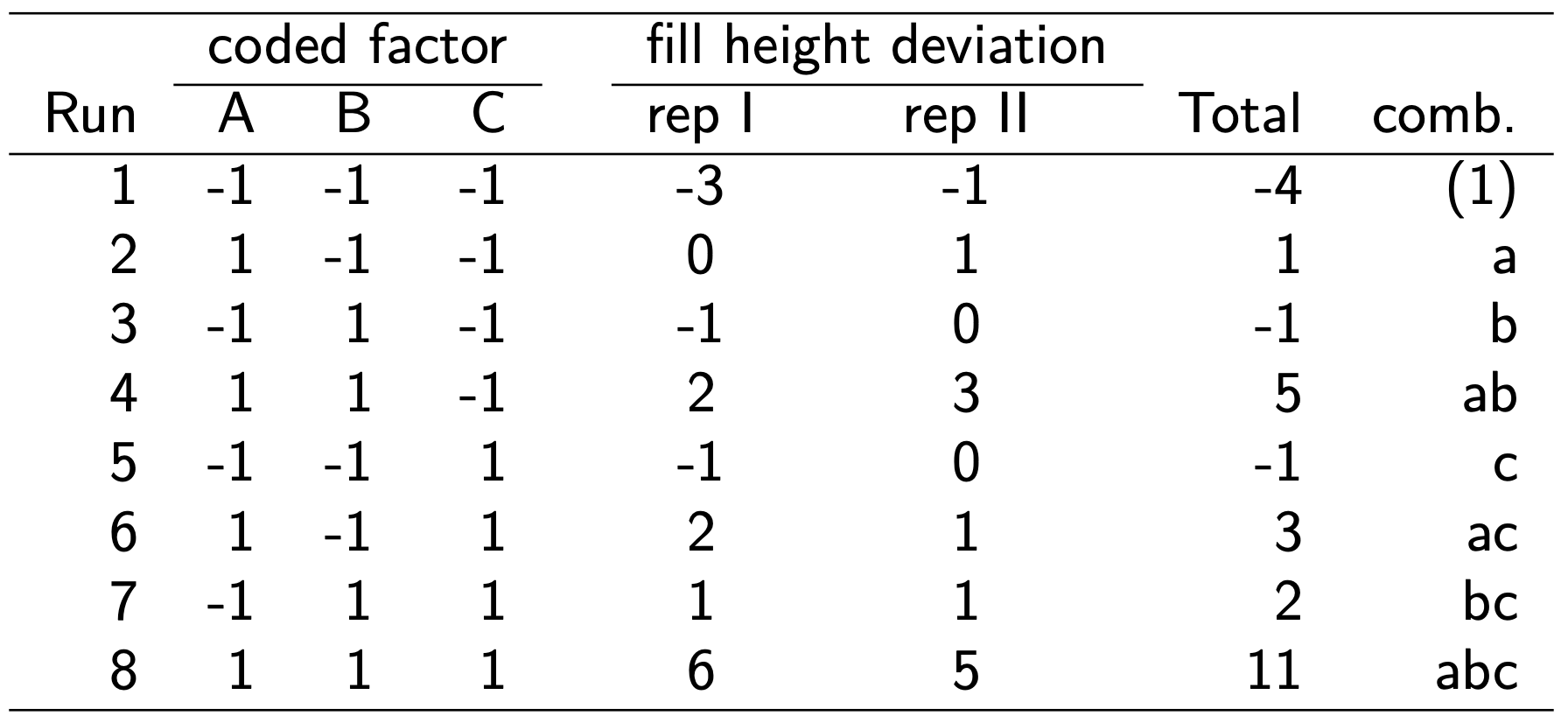
Standard order \(\rightarrow\)\((1), a, b, ab, c, ac, bc\), and \(abc\).
Remember that these symbols also represent the total of all \(n\) observations taken at that particular treatment combination.
Three different notations for \(2^3\) design:
Effects in the \(2^3\) design
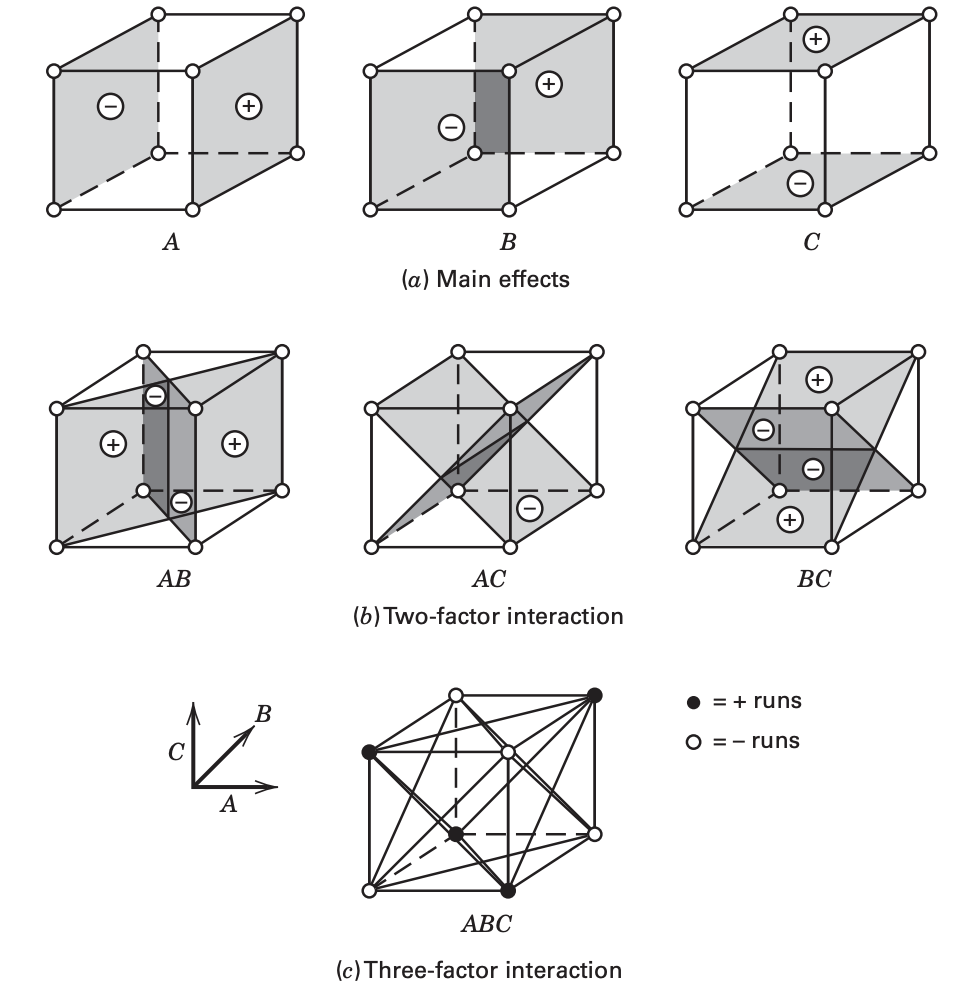
Main effects: \(A\), \(B\), and \(C\)
Two-factor interactions: \(AB\), \(AC\), \(BC\)
Three-factor interaction: \(ABC\)
The \(A\) effect is just the average of the four runs where \(A\) is at the high level \(\left(\bar{y}_{A^{+}}\right)\) minus the average of the four runs where \(A\) is at the low level \(\left(\bar{y}_{A^{-}}\right)\), \[
\begin{aligned}
A & =\bar{y}_{A^{+}}-\bar{y}_{A^{-}} \\
& =\frac{a+a b+a c+a b c}{4 n}-\frac{(1)+b+c+b c}{4 n}
\end{aligned}
\]
This equation can be rearranged as \[
A =\frac{1}{4 n}[a+a b+a c+a b c-(1)-b-c-b c]
\]
Similarly \[
\begin{aligned}
B &=\frac{1}{4 n}[b+a b+b c+a b c-(1)-a-c-a c] \\
C &=\frac{1}{4 n}[c+a c+b c+a b c-(1)-a-b-a b]
\end{aligned}
\]
The quantities in brackets are contrasts in the treatment combinations
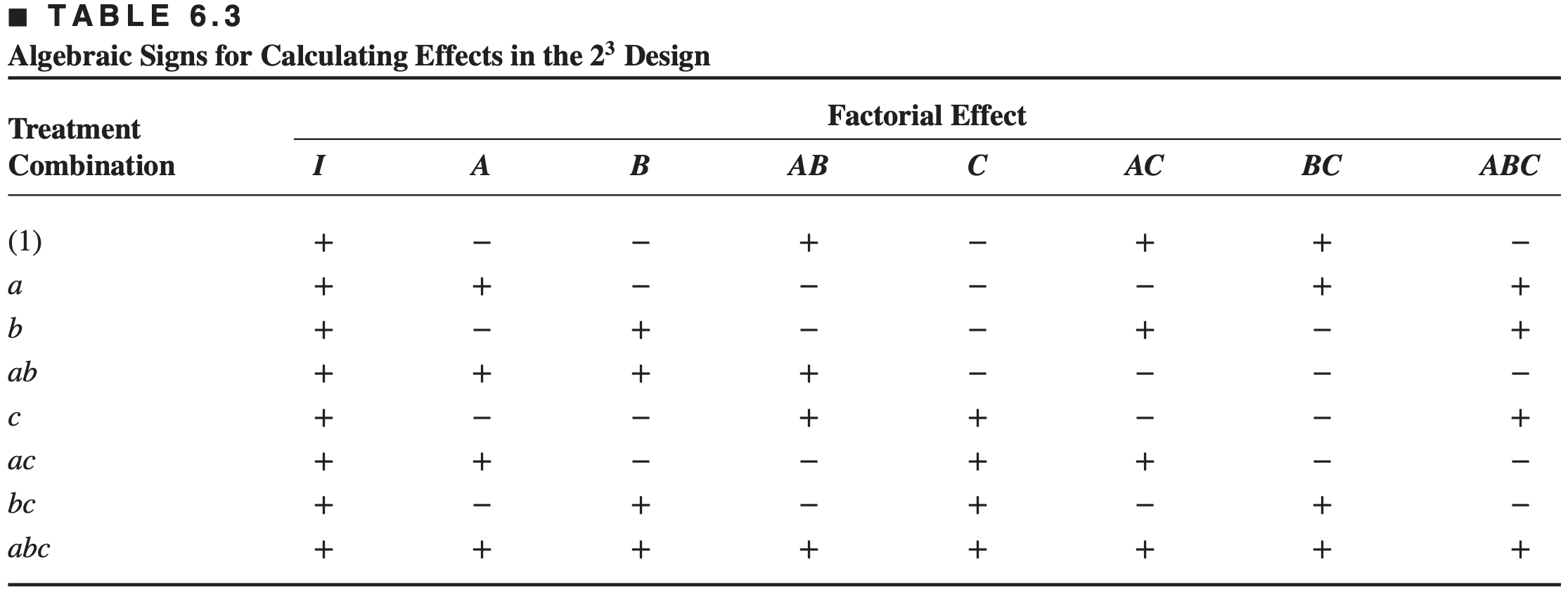
Table of plus and minus signs for calculating effects
The column for \(A, B\), abd \(C\) are actually from the design matrix.
This table actually contains all the contrasts.
Construction of plus and minus table:
Signs for the main effects are determined by associating a plus with the high level and a minus with the low level.
Once the signs for the main effects have been established, the signs for the remaining columns can be obtained by multiplying the appropriate preceding columns
Interesting properties of Table of plus and minus signs:
Except the column \(I\), every column has an equal number of \(+\) and \(-\) signs
The sum of the products of any two columns is zero
The column \(I\) multiplied any column leaves the column unchanged, column \(I\) is known as identity column
Product of any two columns yields a column in the table, e.g. \(A \times B = AB, \quad AB \times BC = AB^2C = AC \;(\text{mod 2})\).
Exponents in the products are formed by using modulus 2 arithmetic.
Property-2 indicates that it is an Orthogonal design
Sum of squares
In the \(2^3\) design with \(n\) replicates, the sum of squares for any effect is \[
SS = \frac{\text{Contrast}^2}{2^3 n}= \frac{\text{Contrast}^2}{8 n}
\]
The \(2^3\) design: An example
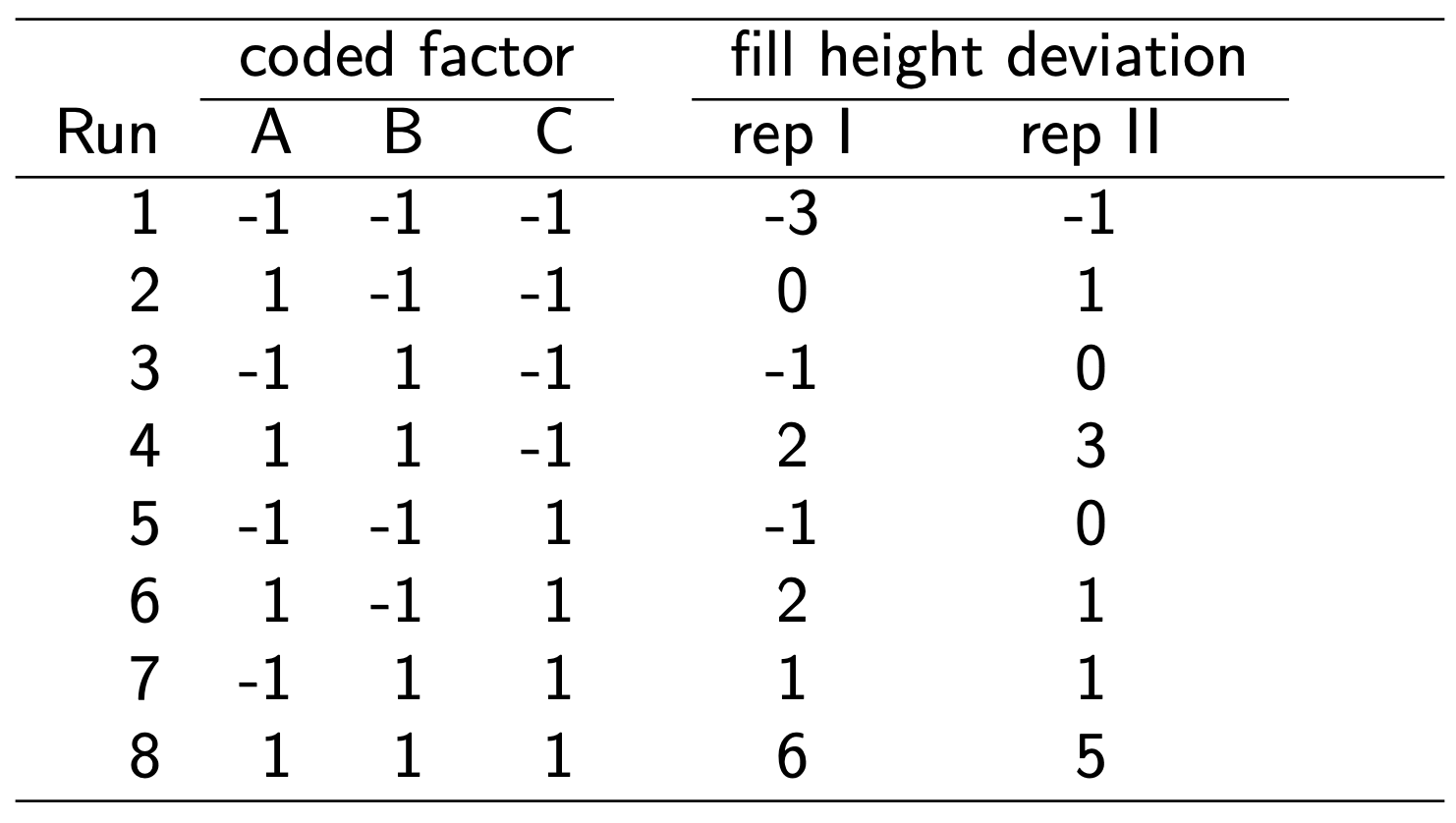
A soft drink bottler is interested in obtaining more uniform fill heights in the bottles produced his manufacturing process.
The filling machine theoretically fills fills each bottle to the correct target height, but in practice, there is variation around this target.
The bottler would like to understand better the sources of variability and eventually reduce it.
The process engineer can control three factors during the filling process: percentage of carbonation (A), operating pressure (B), and line speed (C).
Each factor has two levels: A (10% and 12%), B (25 psi and 30 psi), and C (200 b/min and 300 b/min).
The data:
Notation for the response: \(y_{ijkl}, \; i, j, k, l=1,2\)
Estimation of effects
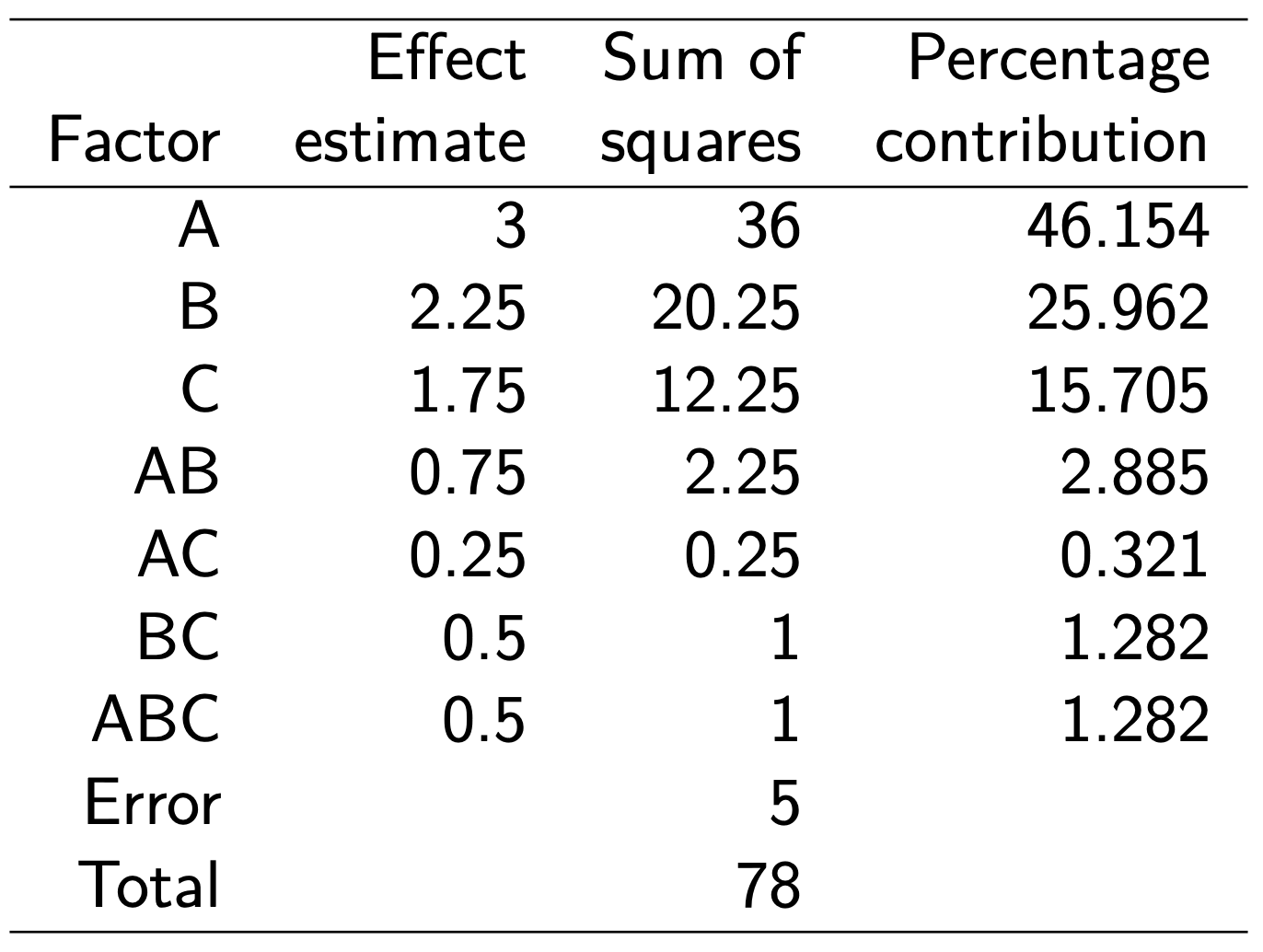
Main effect of A \[\begin{align*}
A &= (abc + ab + ac + a - bc - b - c - (1))/4n \\
&= (11 + 5 + 3 + 1 - 2 + 1 + 1 +4)/8 \\
&= 24/8\\
&= 3
\end{align*}\] Similarly, \[\begin{align*}
B &= (abc + ab + bc + b - ac - a - c - (1))/4n
= 2.25 \\~\\
C &= (abc + ac + bc + c - ab - a - b - (1))/4n
= 1.75
\end{align*}\]
Interactions \[\begin{align*}
AB &= (abc + ab + c + (1) - ac - bc - a - b)/4n
=0.75 \\~\\
AC &= (abc + ac + b + (1) - ab - bc - a - c)/4n
=0.25 \\~\\
BC &= (abc + bc + a + (1) - ab - ac - b -c)/4n
=0.5\\~\\
ABC &= (abc + a + b + c - ab - ac - bc - (1))/4n
=0.5
\end{align*}\]
Percentage contribution is a rough but effective guide to the relative importance of each model term. Main effects dominate the process accounting for over 87 percent of the total variation.
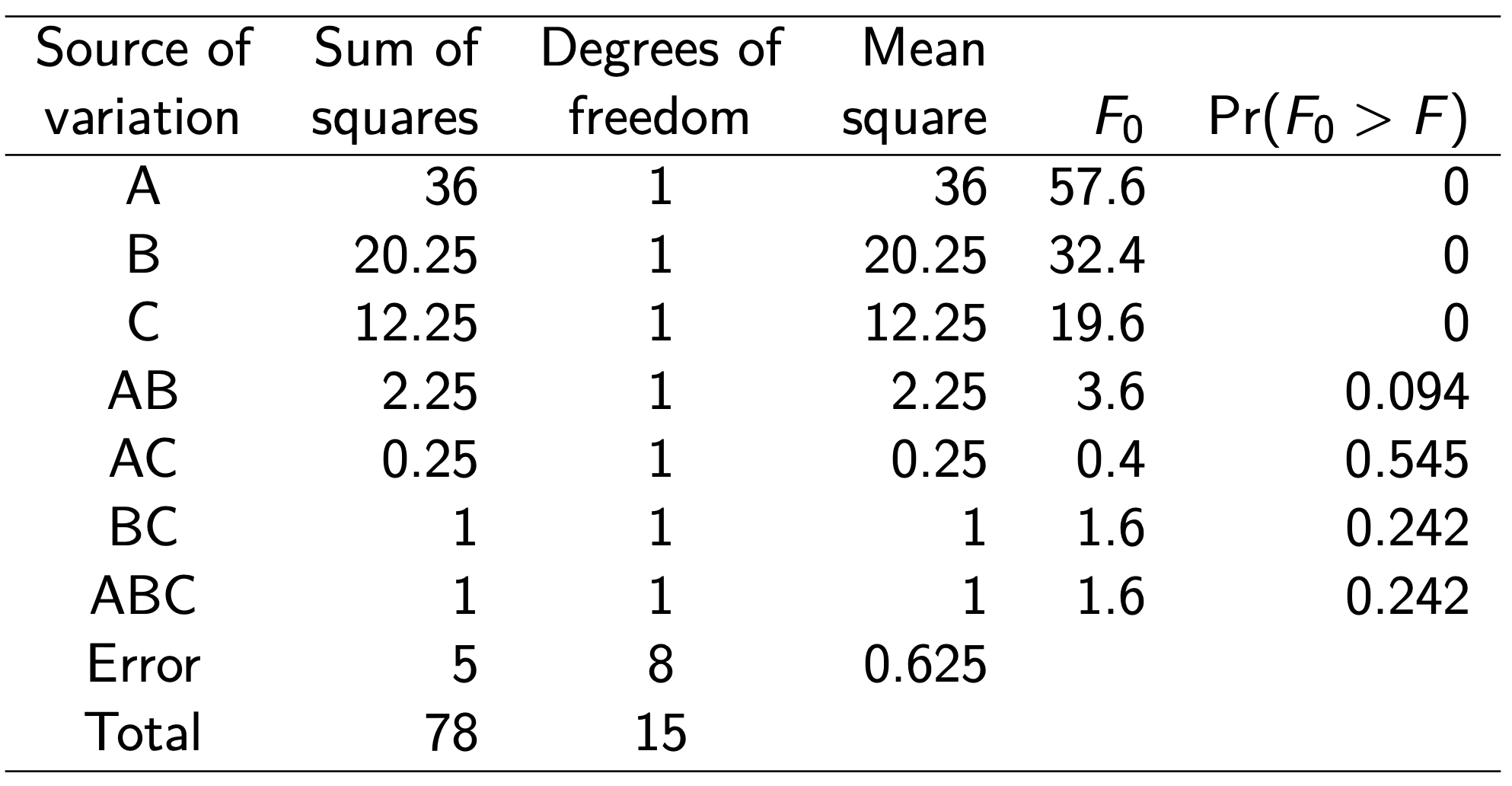
Analysis of variance table
All the main effects are highly significant and only the interaction between carbonation and pressure is significant at about 10 percent level of significance.
The model sum of squares is \[
S S_{\text {Model }}=S S_A+S S_B+S S_C+S S_{A B}+S S_{A C}+S S_{B C}+S S_{A B C}
\]
Thus the statistic \[
F_0=\frac{M S_{\text {Model }}}{M S_E}
\] is testing the hypotheses \[
H_0: \beta_1=\beta_2=\beta_3=\beta_{12}=\beta_{13}=\beta_{23}=\beta_{123}=0
\]\(H_1\) : at least one \(\beta \neq 0\)
If \(\mathrm{F}_0\) is large, we would conclude that at least one variable has a nonzero effect. Then each individual factorial effect is tested for significance using the \(F\) statistic.
\[
R^2=\frac{S S_{\text {Model }}}{S S_{\text {Total }}}
\] It measures the proportion of total variability explained by the model.
A potential problem with this statistic is that it always increases as factors are added to the model, even if these factors are not significant. The adjusted \(\mathrm{R}^2\) statistic, defined as \[
R_{\text {Adj }}^2=1-\frac{S S_E / d f_E}{S S_{\text {Total }} / d f_{\text {Total }}}
\]
\(R_{\text {Adj }}^2\) is a statistic that is adjusted for the “size” of the model, that is, the number of factors.
The adjusted \(\mathrm{R}^2\) can actually decrease if nonsignificant terms are added to a model. The standard error of each coefficient, defined as \[
s e(\hat{\beta})=\sqrt{V(\hat{\beta})}=\sqrt{\frac{M S_E}{n 2^k}}=\sqrt{\frac{M S_E}{N}}
\]
The 95 percent confidence intervals on each regression coefficient are computed from \[
\hat{\beta}-t_{0.025, N-p} \operatorname{se}(\hat{\beta}) \leq \beta \leq \hat{\beta}+t_{0.025, N-p} \operatorname{se}(\hat{\beta})
\] where the degrees of freedom on \(t\) are the number of degrees of freedom for error; that is, \({N}\) is the total number of runs in the experiment (16), and \({p}\) is the number of model parameters (8).
Other Methods for Judging the Significance of Effects.
The analysis of variance is a formal way to determine which factor effects are nonzero. Several other methods are useful. Now, we show how to calculate the standard error of the effects, and we use these standard errors to construct confidence intervals on the effects.
Confidence Interval of the Effect:
The \(100(1-\alpha)\) percent confidence intervals on the effects are computed from \[\operatorname{Effect} \pm \,{t}_{\alpha / 2, {~N}-{p}} * \operatorname{se}(\operatorname{Effect}),\] where \[
se(\text {Effect})=\frac{2 S}{\sqrt{n 2^k}}, \quad \text{where} \quad S^2=M S_E
\]
Regression analysis with R
# Define the response variabley3 <-c(-3, 0, -1, 2, -1, 2, 1, 6,-1, 1, 0, 3, 0, 1, 1, 5)# Create treatment variablesxA <-rep(c(-1, 1), each =1, times =8)xB <-rep(c(-1, 1), each =2, times =4)xC <-rep(c(-1, 1), each =4, times =2)# Fit the linear modelreg.y3 <-lm(y3 ~ xA + xB + xC + xA:xB)coef(reg.y3)
(Intercept) xA xB xC xA:xB
1.000 1.500 1.125 0.875 0.375
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
xA 1 36.00 36.000 54.6207 1.376e-05 ***
xB 1 20.25 20.250 30.7241 0.0001746 ***
xC 1 12.25 12.250 18.5862 0.0012327 **
xA:xB 1 2.25 2.250 3.4138 0.0916999 .
Residuals 11 7.25 0.659
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
anova(res3, res2)
Analysis of Variance Table
Model 1: y ~ xA + xB + xC + xA:xB
Model 2: y ~ xA * xB * xC
Res.Df RSS Df Sum of Sq F Pr(>F)
1 11 7.25
2 8 5.00 3 2.25 1.2 0.37
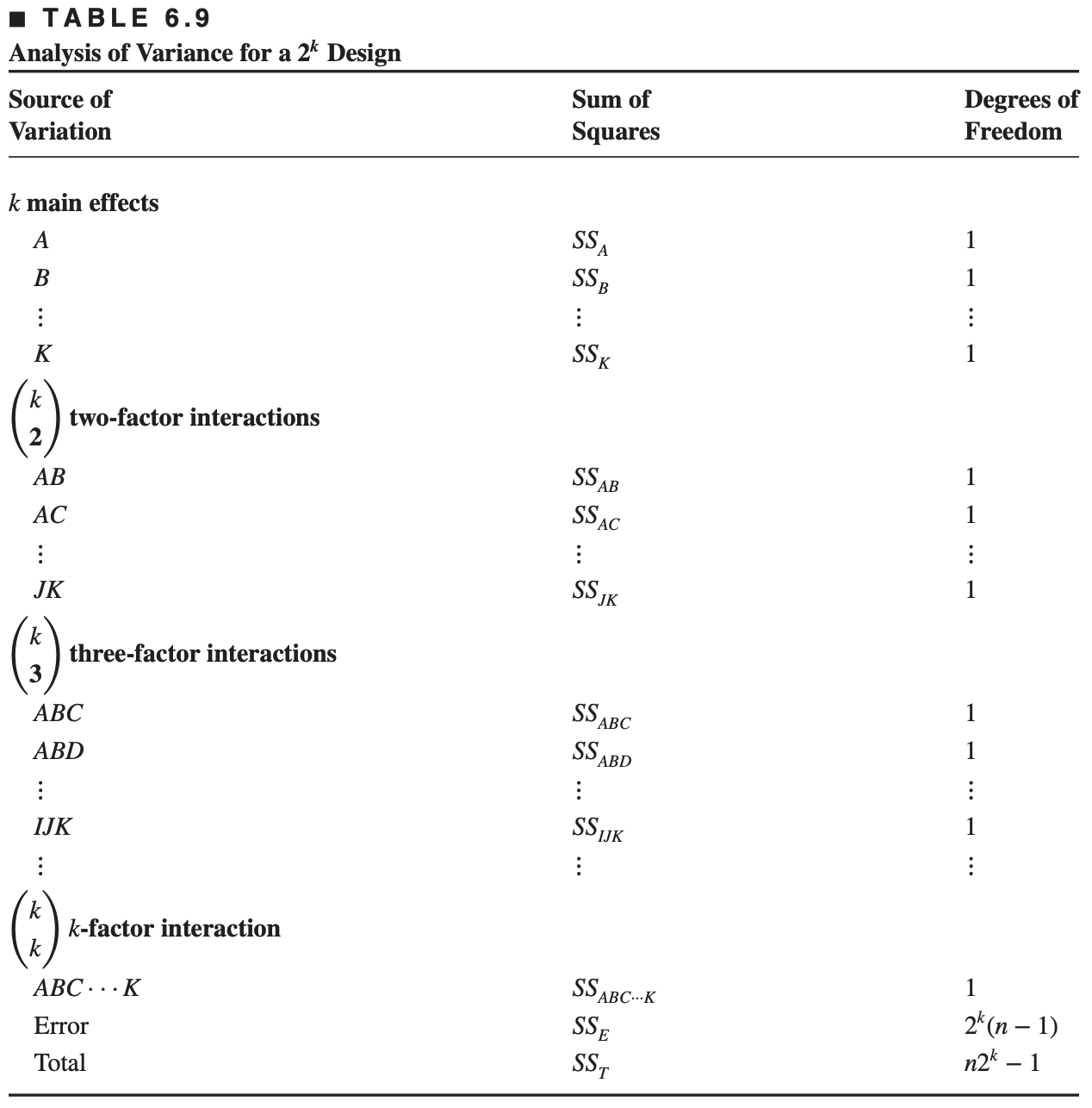
6.4 The general \(2^k\) design
The general \(2^k\) design
The \(2^k\) factorial design is a design with \(k\) factors each has two levels.
A statistical model for \(2^k\) design would include
\(k\) main effects
\(k\choose 2\) two-factor interactions
\(k\choose 3\) three-factor interactions
\(\ldots\)
one \(k\)-factor interaction
For a \(2^k\) design, the complete model would contain \(2^k-1\) effects
The treatment combinations can be written in a standard order, e.g. \[
(1)\; a \; b \; ab \; c \;ac \; bc \; abc \; d \; ad \; \cdots
\]
The complete model for \(2^k\) design with \(n\) replications has
\(n2^k-1\) total degrees of freedom
\((n2^k-1) - (2^k -1) = 2^k(n-1)\) error degrees of freedom
For a \(2^k\) design, contrast for the effect \(AB\cdots K\) can be expressed as \[\text{Contrast}_{AB\cdots} = (a\pm 1)(b\pm 1)\cdots (k\pm 1)\]
ordinary algebra is used with “1” being replaced by (1) in the final expression.
The sign in each set of parentheses is negative if the factor is included in the effect and positive if the factor is not included.
E.g. for a \(2^2\) design, the contrast \[\begin{align*}
A &= (a-1)(b+1)=ab + a - b - (1)\\
AB &= (a-1)(b-1) = ab -a - b + (1)
\end{align*}\]
Estimate of the contrast \[
AB\ldots K = \frac{2}{n2^k}\,[\text{Contrast}_{AB\cdots K}]
\]
Sums of squares \[
SS_{AB\ldots K} = \frac{1}{n2^k}\,[\text{Contrast}_{AB\cdots K}]^2,
\] where \(n\) is the number of replications.
6.5 A single replicate of the \(2^k\) design
Total number of treatment combinations in a \(2^k\) factorial design could be very large even for a moderate number of factors
For example, a \(2^5\) design has 32 treatment combinations, a \(2^6\) design has 64 treatment combinations, and so on
In many practical situations, the available resources may only allow a single replicate of the design to be run
Single replicate may cause problem if the response is highly variable
A single replicate of a \(2^k\) design is sometime called an unreplicated factorial
With only one replicate, pure error cannot be estimated, so commonly used analysis of variance cannot be performed
Two approaches are commonly used for analysing unreplicated factorial design
Consider certain high-order interactions as negligible and combine their mean squares to estimate the error.
This approach is based on the assumption that the most systems is dominated by some of the main effects and low-order interactions, and most of the high-order interactions are negligible (sparsity of effects principle)
Higher-order interactions could be of interest, in that case polling higher-order interactions to estimate the error variance is not appropriate.
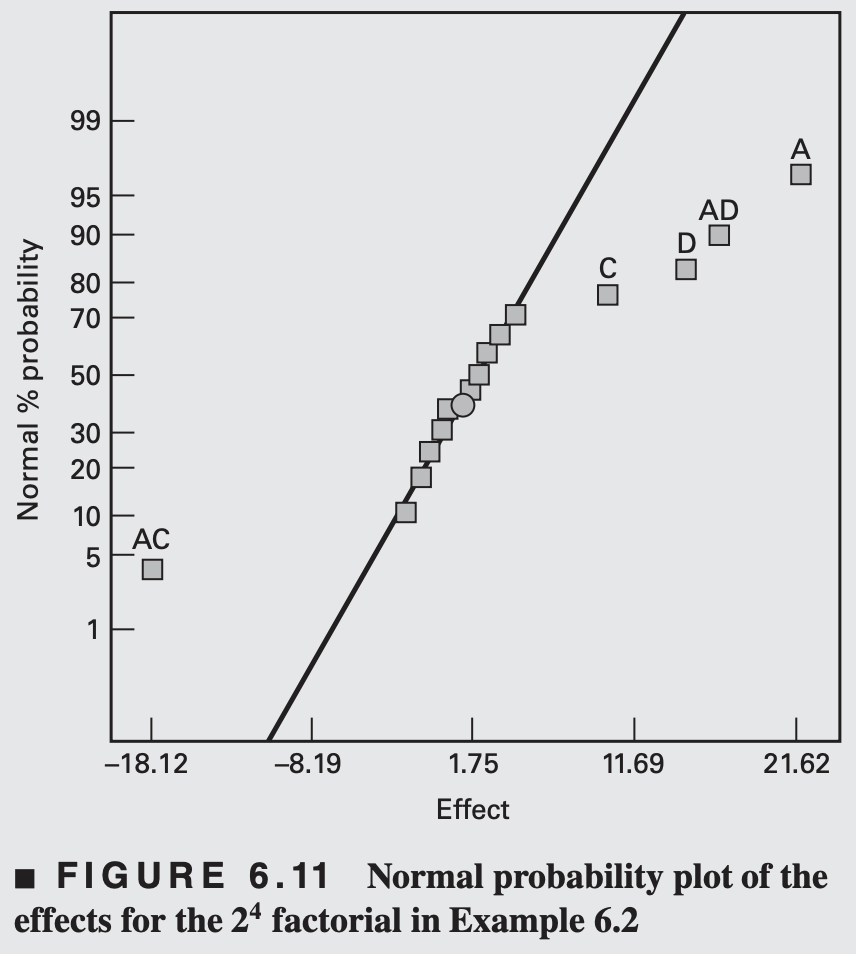
In such case, normal probability plots of the effect estimates could be of help. The negligible effects should be normally distributed with mean 0 and variance \(\sigma^2\) and will fall in a straight line on the plot. On the other hand, significant effects will have nonzero means and will not lie along the straight line.
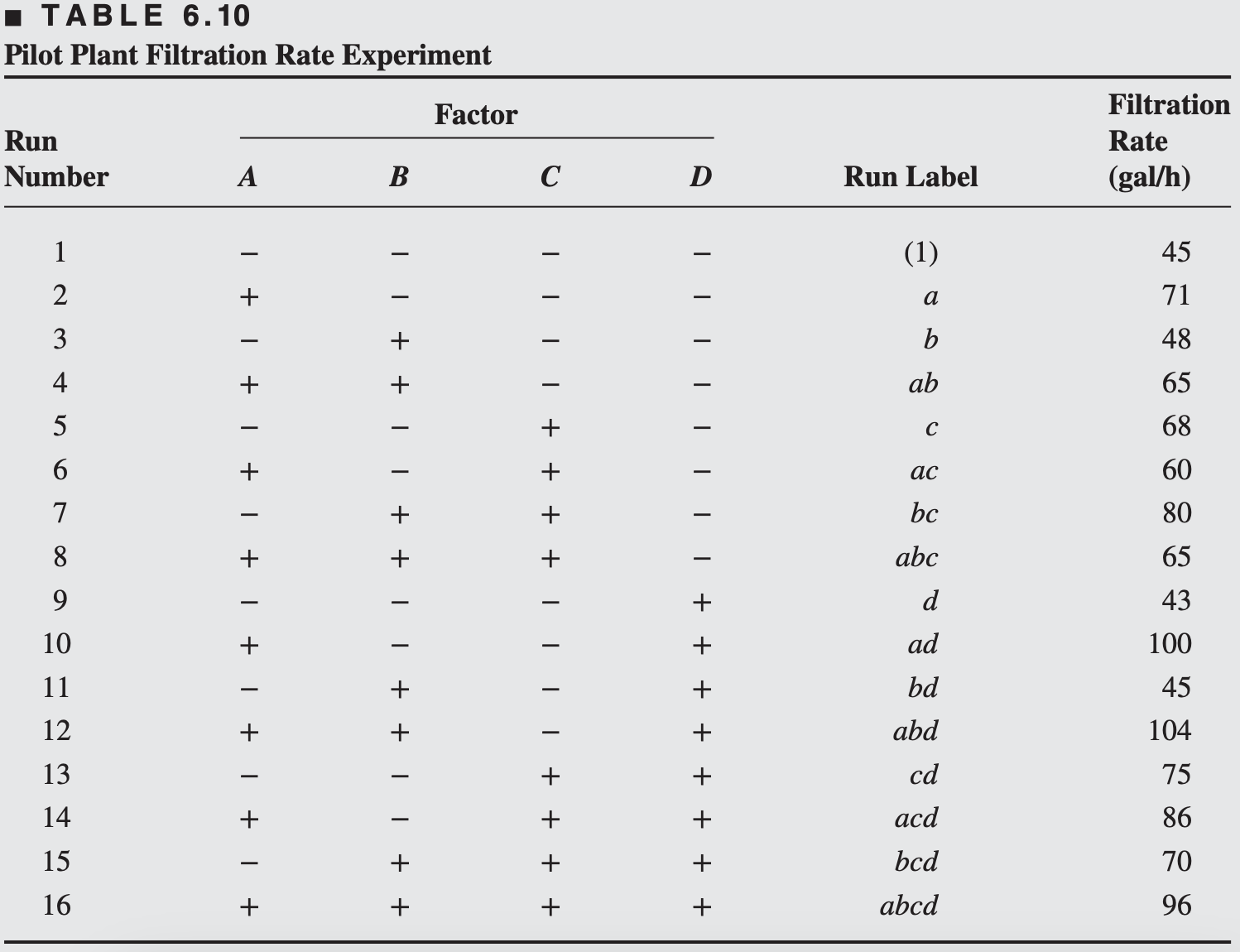
EXAMPLE 6.2
A chemical product is produced in a pressure vessel. A factorial experiment is carried out in the pilot plant to study the factors thought to influence the filtration rate of this product.
Four factors temperature (A), pressure (B), concentration of formaldehyde (C), and stirring rate (D) are thought to be important for the chemical product.
The design matrix and the response data obtained from a single replicate of the \(2^4\) experiment are shown in Table 6.10.
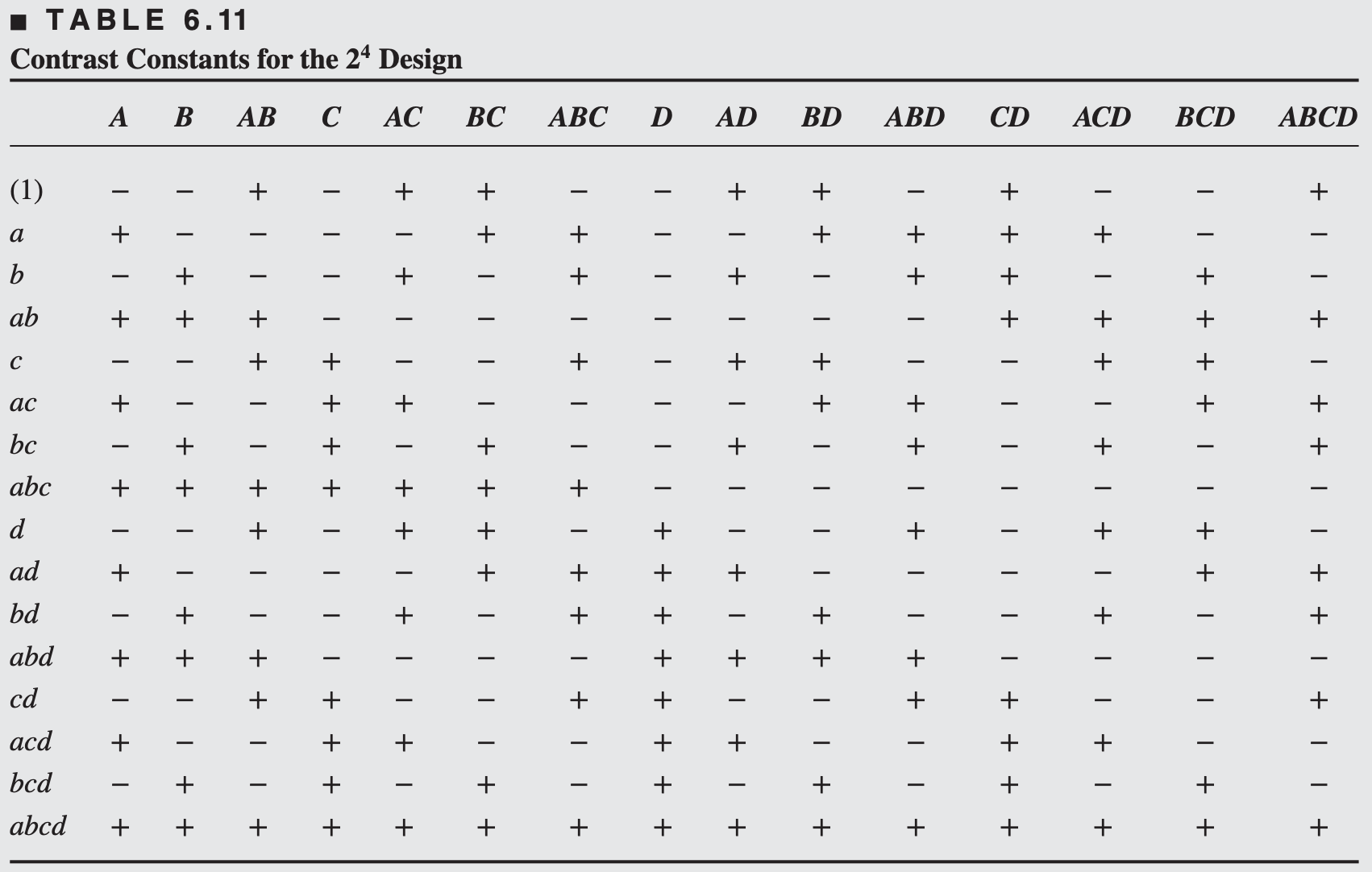
We will begin the analysis of these data by constructing a normal probability plot of the effect estimates.
The table of plus and minus signs for the contrast constants for the \(2^4\) design are shown in Table 6.11.
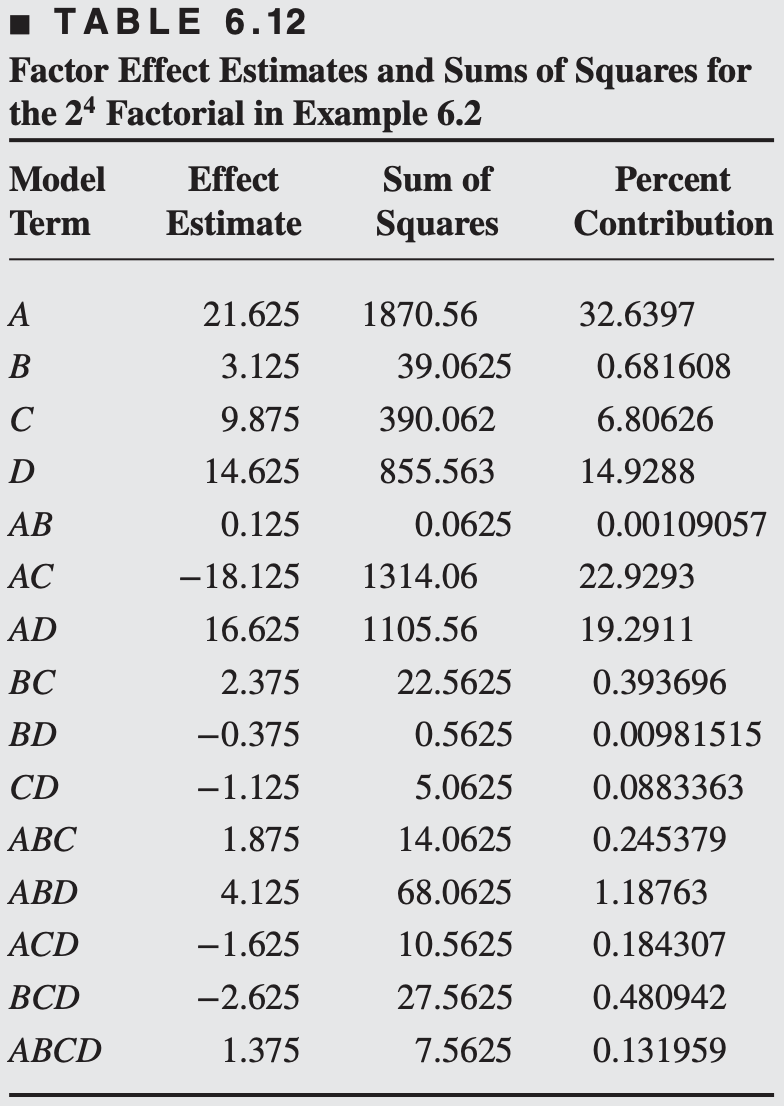
From these contrasts, we may estimate the 15 factorial effects and the sums of squares shown in Table 6.12.
df <-data.frame(y =c(45, 71, 48, 65, 68, 60, 80, 65, 43, 100, 45, 104, 75, 86, 70, 96),A =rep(c(-1, 1), times =8),B =rep(c(-1, 1), each =2, times =4),C =rep(c(-1, 1), each =4, times =2),D =rep(c(-1, 1), each =8))model <-lm(y ~ A * B * C * D, data = df)dat6b <-tibble(`Model terms`=c('A', 'B', 'C', 'D', 'AB', 'AC', 'BC','AD', 'BD', 'CD', 'ABC', 'ABD', 'ACD', 'BCD', 'ABCD'),`Effect estimates`=coef(model)[-1] *2,SS =anova(model)$"Sum Sq"[1:15],`Percentage contribution`=100* (SS /sum(SS)))
kableExtra::kable(dat6b, digits =3, align ='c')
Model terms
Effect estimates
SS
Percentage contribution
A
21.625
1870.562
32.640
B
3.125
39.062
0.682
C
9.875
390.063
6.806
D
14.625
855.563
14.929
AB
0.125
0.062
0.001
AC
-18.125
1314.062
22.929
BC
2.375
22.562
0.394
AD
16.625
1105.562
19.291
BD
-0.375
0.563
0.010
CD
-1.125
5.063
0.088
ABC
1.875
14.063
0.245
ABD
4.125
68.062
1.188
ACD
-1.625
10.563
0.184
BCD
-2.625
27.563
0.481
ABCD
1.375
7.563
0.132
The important effects that emerge from this analysis are
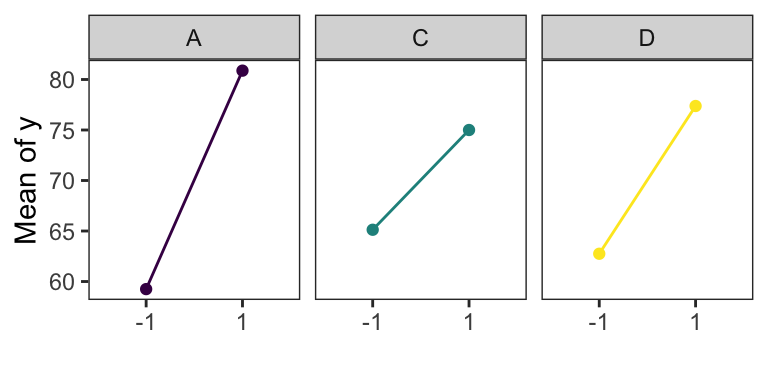
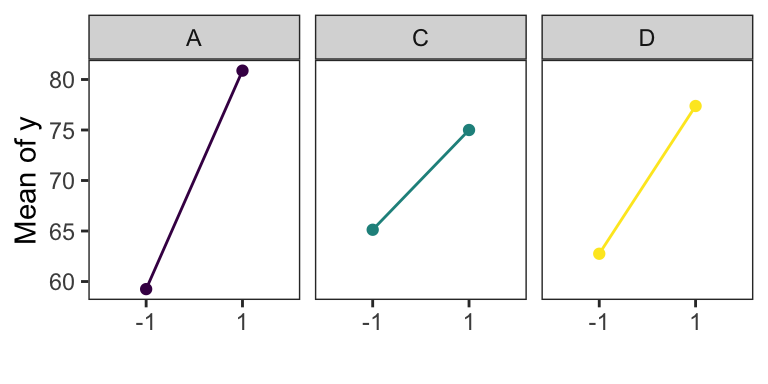
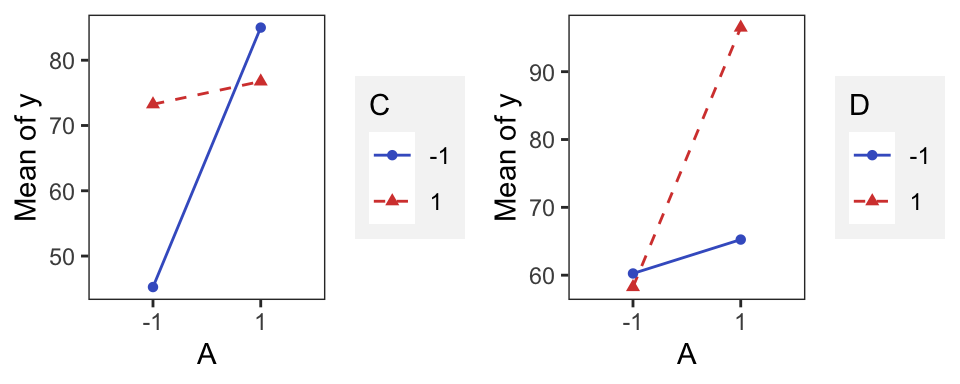
The main effects of A, C, and D are plotted in Figure. All three effects are positive, and if we considered only these main effects, we would run all three factors at the high level to maximize the filtration rate.
However, it is always necessary to examine any interactions that are important. Remember that main effects do not have much meaning when they are involved in significant interactions.
The AC interaction indictates: the \(A\) effect is very small when the \(C\) is at the high level and very large when the \(C\) is at the low level, with the best results obtained with low C and high A.
The AD interaction indicates: \(D\) has little effect at low \(A\) but a large positive effect at high \(A\).
Therefore, the best filtration rates would appear to be obtained when A and D are at the high level and C is at the low level. This would allow the reduction of the formaldehyde concentration to a lower level, another objective of the experimenter.
Design projection
Another interpretation of the effects in Figure 6.11 is possible
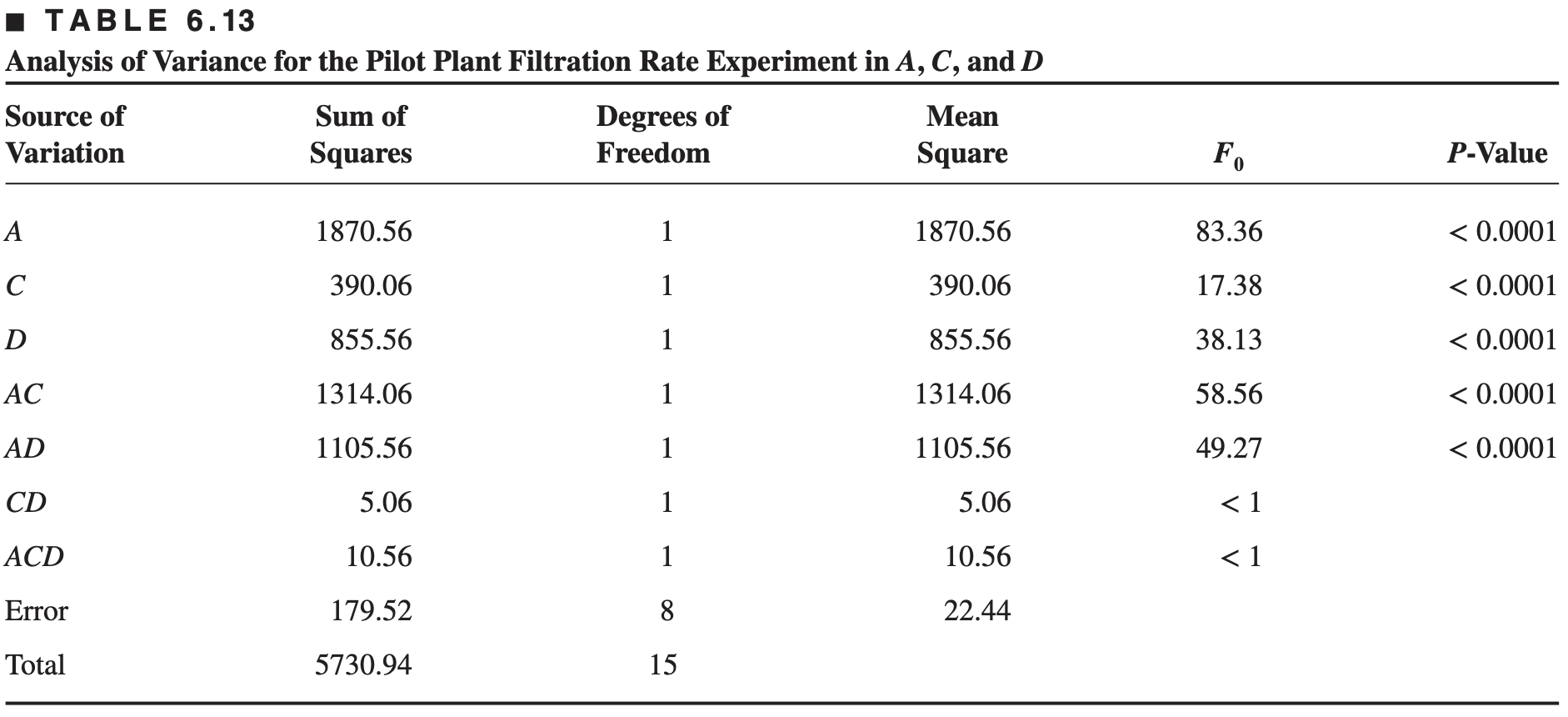
Because \(B\) (pressure) is not significant and all interactions involving \(B\) are negligible, we may discard \(B\) from the experiment so that the design becomes a \(2 ^3\) factorial in \(A, C,\) and \(D\) with two replicates.
This is easily seen from examining only columns \(A, C,\) and \(D\) in the design matrix shown in Table 6.10 and noting that those columns form two replicates of a \(2^3\) design.
The analysis of variance for the data using this simplifying assumption is summarized in Table 6.13.
The conclusions that we would draw from this analysis are essentially unchanged from those of Example 6.2.
Note that by projecting the single replicate of the \(2^4\) into a replicated \(2^3\) , we now have both an estimate of the \(ACD\) interaction and an estimate of error based on what is sometimes called hidden replication
In general, if we have a single replicate of a \(2 ^k\) design, and if \(h (h < k)\) factors are negligible and can be dropped, then the original data correspond to a full two-level factorial in the remaining \(k - h\) factors with \(2^ h\) replicates.
The Half-Normal Plot of Effects
An alternative to the normal probability plot of the factor effects is the half-normal plot.
This is a plot of the absolute value of the effect estimates against their cumulative normal probabilities.
The straight line on the half-normal plot always passes through the origin and should also pass close to the fiftieth percentile data value.
ggDoE::half_normal(model)
Other Methods for Analyzing Unreplicated Factorials.
A widely used analysis procedure for an unreplicated two-level factorial design is the normal (or half-normal) plot of the estimated factor effects.
However, unreplicated designs are so widely used in practice that many formal analysis procedures have been proposed to overcome the subjectivity of the normal probability plot.
Hamada and Balakrishnan (1998) compared some of these methods.
They found that the method proposed by Lenth (1989) has good power to detect significant effects. It is also easy to implement, and as a result it appears in several software packages for analyzing data from unreplicated factorials.
6.6 Additional Examples of Unreplicated \(2^k\) Designs
EXAMPLE 6.3: Data Transformation in a Factorial Design
6.7\(2^k\) Designs are Optimal Designs
The model parameter regression coefficients (and effect estimates) from a \(2^k\) design are least squares estimates. For a \(2^2\) model, the regression model is \[y=\beta_0+\beta_1 x_1+\beta_2 x_2+\beta_{12} x_1 x_2+\varepsilon\]
The four observations from a \(2^2\) design: \[
\begin{aligned}
& (1)=\beta_0+\beta_1(-1)+\beta_2(-1)+\beta_{12}(-1)(-1)+\varepsilon_1 \\
& a=\beta_0+\beta_1(1)+\beta_2(-1)+\beta_{12}(1)(-1)+\varepsilon_2 \\
& b=\beta_0+\beta_1(-1)+\beta_2(1)+\beta_{12}(-1)(1)+\varepsilon_3 \\
& a b=\beta_0+\beta_1(1)+\beta_2(1)+\beta_{12}(1)(1)+\varepsilon_1
\end{aligned}
\]
The least squares estimate of \(\beta\) is given by: \[
\hat{\beta} = (X'X)^{-1} X'y
\]
Since this is an orthogonal design, the \(X'X\) matrix is diagonal:
\[
\hat{\beta} =
\begin{bmatrix}
4 & 0 & 0 & 0 \\
0 & 4 & 0 & 0 \\
0 & 0 & 4 & 0 \\
0 & 0 & 0 & 4 \\
\end{bmatrix}^{-1}
\begin{bmatrix}
(1) + a + b + ab \\
a + ab - b - (1) \\
b + ab - a - (1) \\
(1) - a - b + ab \\
\end{bmatrix}
\]
With this, we obtain:
\[
\begin{bmatrix}
\hat{\beta}_0 \\
\hat{\beta}_1 \\
\hat{\beta}_2 \\
\hat{\beta}_{12} \\
\end{bmatrix}
= \frac{1}{4} \mathbf{I}_4
\begin{bmatrix}
(1) + a + b + ab \\
a + ab - b - (1) \\
b + ab - a - (1) \\
(1) - a - b + ab \\
\end{bmatrix}
=
\begin{bmatrix}
\frac{(1) + a + b + ab}{4} \\
\frac{a + ab - b - (1)}{4} \\
\frac{b + ab - a - (1)}{4} \\
\frac{(1) - a - b + ab}{4} \\
\end{bmatrix}
\]
The “usual” contrasts are shown in the matrix of \(X'y\).
The \(X'X\) matrix is diagonal as a consequence of the orthogonal design.
The regression coefficient estimates are exactly half of the “usual” effect estimates.
The matrix (X’X) has some useful properties
\[
\begin{aligned}
V(\hat{\beta}) &= \sigma^2 \, (\text{diagonal element of } (X'X)^{-1}) \\
&= \frac{\sigma^2}{4} \quad \longrightarrow \quad \text{Minimum possible value for a four-run design}
\end{aligned}
\]
\[
|X'X| = 256 \quad \longrightarrow \quad \text{Maximum possible value for a four-run design}
\]
Notice that these results depend on both the design you have chosen and the model.
It turns out that the volume of the joint confidence region that contains all the model regression coefficients is inversely proportional to the square root of the determinant of \(X′X\).
Therefore, to make this joint confidence region as small as possible, we would want to choose a design that makes the determinant of \(X′X\) as large as possible.
In general, a design that minimizes the variance of the model regression coefficients (or maximize the determinant of \(X′X\)) is called a \(D\)-optimal design.
The \(2^k\) design is a \(D\)-optimal design for fitting the first-order model or the first-order model with interaction.
6.8 The Addition of Center Points to the \(2^k\) Design
A potential concern in the use of two-level factorial designs is the assumption of linearity in the factor effects.
First-order model (with interaction): \[
y=\beta_0+\sum_{j=1}^k \beta_j x_j+\sum \sum_{i<j} \beta_{i j} x_i x_j+\epsilon. \qquad \qquad (6.28)
\] is capable of representing some curvature in the response function.
Second-order model: \[
y=\beta_0+\sum_{j=1}^k \beta_j x_j+\sum_{i<j} \beta_{i j} x_i x_j+\sum_{j=1}^k \beta_{i j} x_j^2+\epsilon \qquad \qquad (6.29)
\] where \(\beta_{jj}\) represent pure Second-order or quadratic effects.
In running a two-level factorial experiment, we usually anticipate fitting the first-order model in Equation 6.28, but we should be alert to the possibility that the second-order model in Equation 6.29 is more appropriate.
There is a method of replicating certain points in a \(2^k\) factorial that will provide protection against curvature from second-order effects as well as allow an independent estimate of error to be obtained.
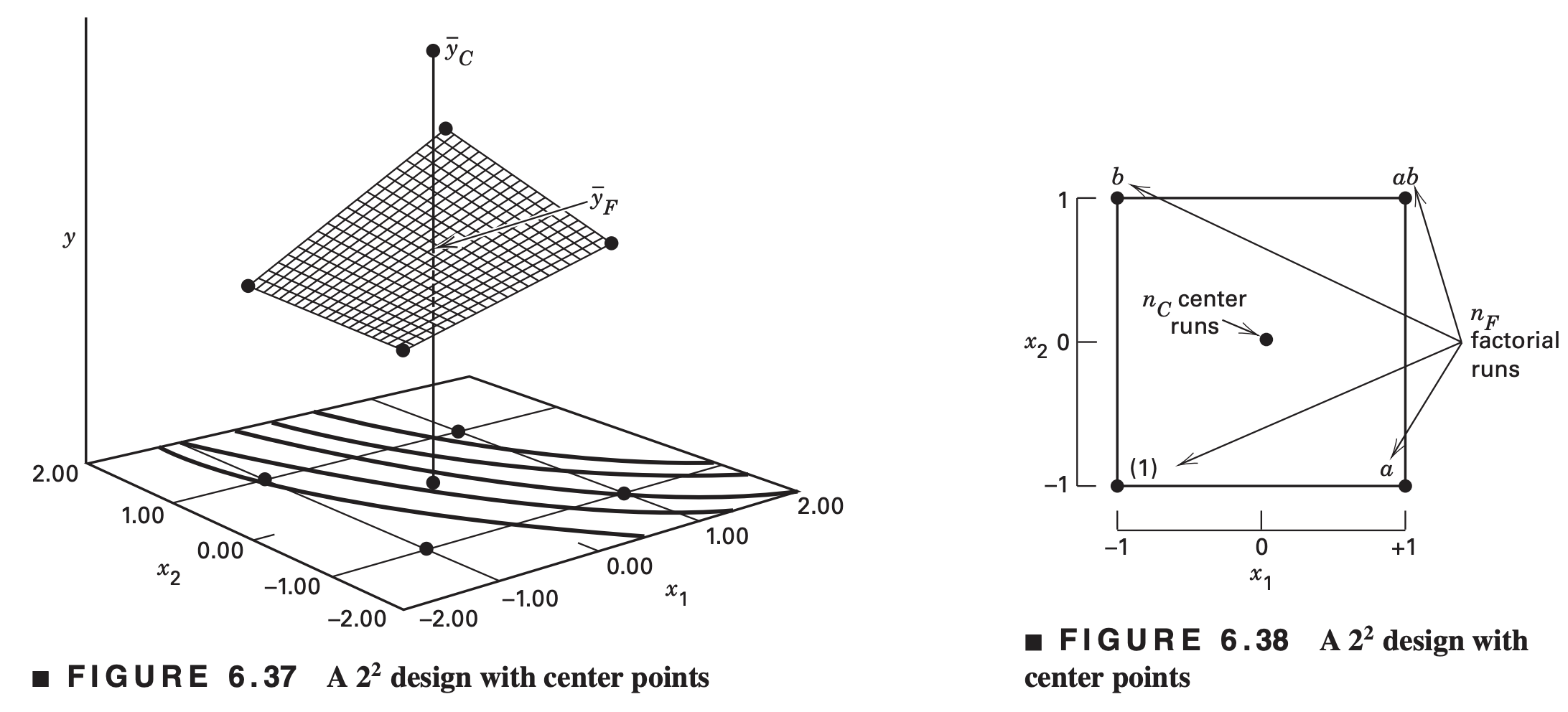
The method consists of adding center points to the \(2^k\) design. These consist of \(n_C\) replicates run at the points \(x_i = 0 (i = 1, 2, \ldots , k)\).
One important reason for adding the replicate runs at the design center is that center points do not affect the usual effect estimates in a \(2^k\) design.
When we add center points, we assume that the \(k\) factors are quantitative.
Let \(\bar{y}_F\) be the average of the \(n_F\) runs at the four factorial points, and \(\bar{y}_C\) be the average of the \(n_C\) runs at the center point.
\(\bar{y}_F\) = \(\bar{y}_C\)\(\rightarrow\) no “curvature” \[
\begin{aligned}
& H_0: \sum_{j=1}^k \beta_{j j}=0 \\
& H_1: \sum_{j=1}^k \beta_{j j} \neq 0
\end{aligned}
\]\[
S S_{\text {Pure quadratic }}=\frac{n_F n_C\left(\bar{y}_F-\bar{y}_C\right)^2}{n_F+n_C} \qquad \qquad (6.30)
\] The sum of square has a single degree of freedom.
This sum of squares may be incorporated into the ANOVA and may be compared to the error mean square to test for pure quadratic curvature.
Furthermore, if the factorial points in the design are unreplicated, one may use the \(n_C\) center points to construct an estimate of error with \(n_C − 1\) degrees of freedom.
Example 6.7 (Extended 6.2)
We will illustrate the addition of center points to a \(2^k\) design by reconsidering the pilot plant experiment in Example 6.2.
Recall that this is an unreplicated \(2^4\) design.
Refer to the original experiment shown in Table 6.10.
Suppose that four center points are added to this experiment, and at the points \(x_1=x_2=x_3=x_4=0\) the four observed filtration rates were \(73,75,66\), and \(69\).
The average of these four center points is \(\bar{y}_C=70.75\)
The average of the 16 factorial runs is \(\bar{y}_F=70.06\).
Since \(\bar{y}_C\) and \(\bar{y}_F\) are very similar, we suspect that there is no strong curvature present.
The mean square for pure error is calculated from the center points as follows: \[
\begin{aligned}
M S_E=\frac{S S_E}{n_C-1} &=\frac{\sum_{\text {Center points }}\left(y_i-\bar{y}_c\right)^2}{n_C-1} \\
&=\frac{\sum_{i=1}^4\left(y_i-70.75\right)^2}{4-1}=16.25
\end{aligned}
\]
The difference \(\bar{y}_F-\bar{y}_C=70.06-70.75=-0.69\) is used to compute the pure quadratic (curvature) sum of squares from Equation 6.30 as follows: \[
\begin{aligned}
S S_{\text {Pure quadratic }} & =\frac{n_F n_C\left(\bar{y}_F-\bar{y}_C\right)^2}{n_F+n_C} \\
& =\frac{(16)(4)(-0.69)^2}{16+4}=1.51
\end{aligned}
\]
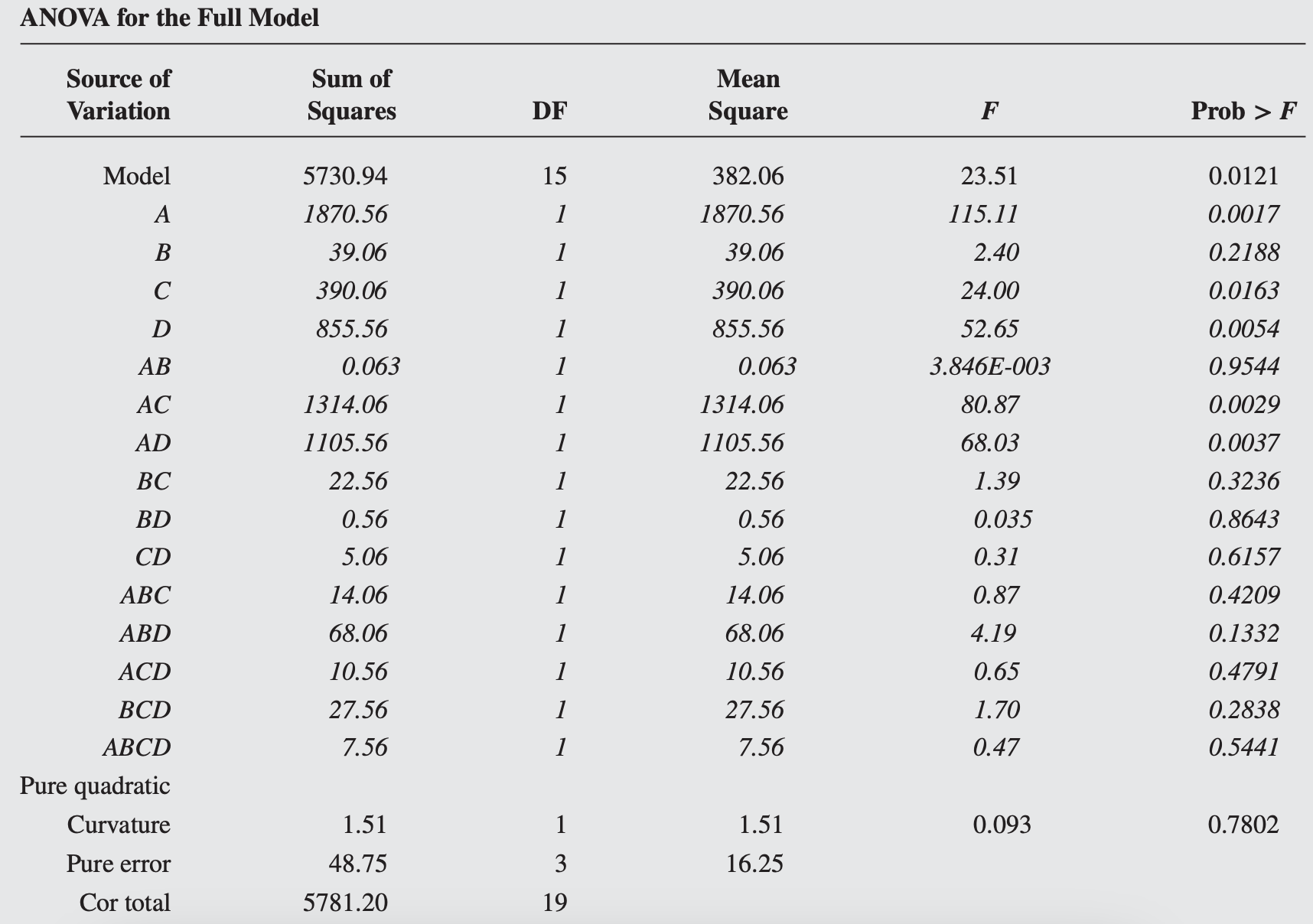
The upper portion of the Table 6.24 shows ANOVA for the full model.
The ANOVA indicates that there is no evidence of second-order curvature in the response over the region of exploration (p-value=0.7802).
That is, the null hypothesis \(H_0: \beta_{11}+\beta_{22}+\)\(\beta_{33}+\beta_{44}=0\) cannot be rejected.
The significant effects are \(A, C, D, A C\), and \(A D\).
The ANOVA for the reduced model is shown in the lower portion of Table 6.24.
The results of this analysis agree with those from Example 6.2, where the important effects were isolated using the normal probability plotting method.