Chapter 13
(AST301) Design and Analysis of Experiments II
13 Experiments with Random Factors
13.1 Introduction
Throughout most of this book we have assumed that the factors in an experiment were fixed factors, that is, the levels of the factors used by the experimenter were the specific levels of interest.
The implication of this, of course, is that the statistical inferences made about these factors are confined to the specific levels studied.
That is, if three material types are investigated as in the battery life experiment of Example 5.1, our conclusions are valid only about those specific material types.
A variation of this occurs when the factor or factors are quantitative. In these situations, we often use a regression model relating the response to the factors to predict the response over the region spanned by the factor levels used in the experimental design.
Several examples of this were presented in Chapters 5 through 9. In general, with a fixed effect, we say that the inference space of the experiment is the specific set of factor levels investigated.
In some experimental situations, the factor levels are chosen at random from a larger population of possible levels, and the experimenter wishes to draw conclusions about the entire population of levels, not just those that were used in the experimental design.
In this situation, the factor is said to be a random factor.
The random effect model was introduced in Chapter 3 for a single-factor experiment, and we used that to introduce the random effects model for the analysis of variance and components of variance.
For example: a company has 50 machines that make cardboard cartons for canned goods, and they want to understand the variation in strength of the cartons.
They choose ten machines at random from the 50 and make 40 cartons on each machine, assigning 400 lots of feedstock cardboard at random to the ten chosen machines.
The resulting cartons are tested for strength. This is a completely randomized design, with ten treatments and 400 units.
Fixed Effects Model
\[ \begin{aligned} y_{ij} &= \mu + \tau_i + \epsilon_{ij} \\ \epsilon_{ij} &\sim N(0, \sigma^2) \end{aligned} \]
- \(\mu\): overall mean
- \(\tau_i\): fixed effect of treatment \(i\)
- \(\epsilon_{ij}\): random error
- \(\tau_i\) are fixed unknown parameters
Random Effects Model
\[ \begin{aligned} y_{ij} &= \mu + \tau_i + \epsilon_{ij} \\ \tau_i &\sim N(0, \sigma^2_\tau) \\ \epsilon_{ij} &\sim N(0, \sigma^2) \end{aligned} \]
- \(\mu\): overall mean
- \(\tau_i\): random effect of treatment \(i\)
- \(\epsilon_{ij}\): random error
- \(\tau_i\) are random variables
Notice that we still decompose the model into: Overall mean (\(\mu\)), Treatment effect (\(\tau_i\)), Random error (\(\epsilon_{ij}\))
Why Fixed-Effects Assumptions Don’t Make Sense in Random Effects Model?
1. Treatment levels are not fixed but randomly sampled
In the fixed-effects model, the treatment levels (e.g., different brands, machines, or methods) are specifically chosen and of interest.
In the random-effects model, these levels are assumed to be a random sample from a larger population of possible treatments.
Therefore, estimating individual treatment effects (\(\tau_i\)) is less meaningful — we care more about the variation among treatments, not their specific values.
2. The focus shifts from estimation to generalization
In fixed-effects, we want to compare specific treatment effects.
In random-effects, we aim to generalize to the broader population of treatments.
So, we’re more interested in estimating variance components (like \(\sigma^2_\tau\)) to understand how much treatments vary, not just how they differ.
3. Inference is about variance components
In random-effects, variability in treatment levels is treated as another source of random variation.
This affects how we partition the total variance and how we perform statistical inference (like testing and confidence intervals).
In this chapter, we focus on methods for the design and analysis of factorial experiments with random factors.
In Chapter 14, we will present nested and split-plot designs, two situations where random factors are frequently encountered in practice.
Review: Random Effects Model
Random effects model is defined only for the random factors, e.g. \[ y_{ij} = \mu + \tau_i + \epsilon_{ij}, \quad i=1,\ldots, a;\;j=1,\ldots,n \] where both \(\tau_i\) and \(\epsilon_{ij}\) are random variables (\(\tau_i\) is not parameter), which are assumed to follow \(\mathcal{N}(0, \sigma^2_\tau)\) and \(\mathcal{N}(0, \sigma^2)\), respectively.
\(\tau_i\) and \(\epsilon_{ij}\) are independent
Variance structure \[ \text{cov}(y_{ij}, y_{i'j'})=\left\{\begin{array}{ll} \sigma_\tau^2 + \sigma^2 & \text{if} \quad i=i',\;j=j'\\ \sigma_\tau^2 & \text{if} \quad i=i',\; j\neq j\\ 0 & \text{if} \quad i\neq i' \end{array}\right. \]
\(\sigma_{\tau}^2\) and \(\sigma^2\) are known as variance components
The parameters of the random effects model are the overall mean \(\mu\), the error variance \(\sigma^2\), and the variance of the treatment effects \(\sigma_\tau^2\); the treatment effects \(\tau_{{i}}\) are random variables, not parameters.
We want to make inferences about these parameters; we are not so interested in making inferences about the \(\tau_{{i}}\) ’s and \(\epsilon_{{ij}}\) ’s.
Typical inferences would be point estimates or confidence intervals for the variance components, or a test of the null hypothesis that the treatment variance \(\sigma_\tau^2\) is 0
Hypothesis considered for the fixed effects model \[ {H_0: \text{no difference between treatment levels}} \] is no longer useful for the random effects model
For random effects model the hypothesis regarding no treatment effects is defined as \[ {H_0: \sigma_\tau^2=0} \quad vs \quad {H_1: \sigma_\tau^2>0} \]
For random effects model, the sum of squares identity \[ SS_T = SS_{Treat} + SS_{E} \] remains valid
It can be shown \[ E(MS_{Treat}) = \sigma^2 + n\sigma^2_\tau \quad \text{and} \quad E(MS_E) = \sigma^2 \]
Under the null hypothesis \(H_0: \sigma^2_\tau=0\), the statistic \[ F_0=\frac{MS_{Treat}}{MS_E} \] follows a \(F\)-distribution with \((a-1)\) and \(a(n-1)\) degrees of freedom
Beside hypothesis testing, estimation of random effects parameters is also of interest in analyzing random effects models
We have \[ E(MS_{Treat}) = \sigma^2 + n\sigma^2_\tau \quad \text{and} \quad E(MS_E) = \sigma^2 \] so the unbiased estimators of \(\sigma^2\) and \(\sigma_\tau^2\) are \[ \hat\sigma^2=MS_E \quad \text{and} \quad \hat\sigma_\tau^2=\frac{MS_{Treat}-MS_E}{n} \]
CI of \(\sigma^2\) can be constructed using the result \[ \frac{a(n-1)MS_E}{\sigma^2} \sim \chi^2_{a(n-1)} \]
We can write the \(100(1-\alpha)\%\) CI \[ \begin{aligned} \text{pr}\Big[\chi^2_{a(n-1), \alpha/2}\leq \frac{a(n-1)MS_E}{\sigma^2}\leq \chi^2_{a(n-1), 1-\alpha/2}\Big]&=1-\alpha\\ \text{pr}\Big[\frac{a(n-1)MS_E}{\chi^2_{a(n-1), 1-\alpha/2}}\leq {\sigma^2}\leq \frac{a(n-1)MS_E}{\chi^2_{a(n-1), \alpha/2}}\Big]&=1-\alpha \end{aligned} \]
- The CI for \(\sigma_\tau^2\) is not straight forward, but it is easy to obtain the CI for \(\sigma_\tau^2/(\sigma^2+\sigma_\tau^2)\) and \(\sigma_\tau^2/\sigma^2\) using the result \[ \frac{MS_{Treat}/(n\sigma_\tau^2+\sigma^2)}{MS_E/\sigma^2}\sim F_{a-1, a(n-1)} \]
Example 3.11
A textile company weaves a fabric on a large number of looms. It would like the looms to be homogeneous so that it obtains a fabric of uniform strength. The process engineer suspects that, in addition to the usual variation in strength within samples of fabric from the same loom, there may also be significant variations in strength between looms. To investigate this, she selects four looms at random and makes four strength determinations on the fabric manufactured on each loom. This experiment is run in random order, and the data obtained are shown in Table 3.17.
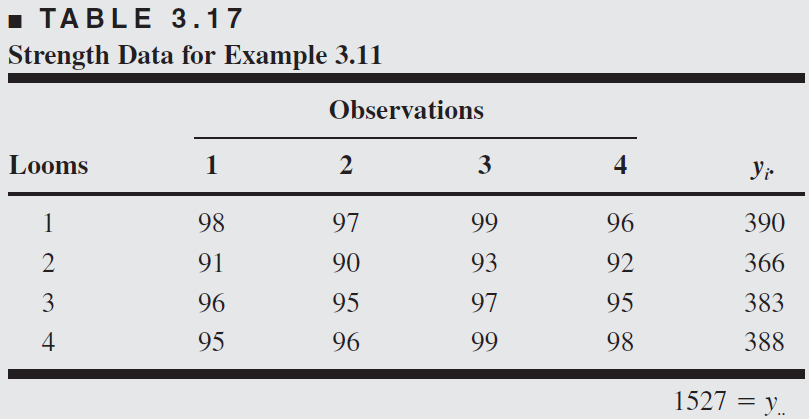
The standard ANOVA partition of the sum of squares is appropriate. There is nothing new in terms of computing.

From the ANOVA, we conclude that the looms in the plant differ significantly.
The variance components are estimated by \(\hat{\sigma}^2=1.90\) and \[ \hat{\sigma}_\tau^2=\frac{29.73-1.90}{4}=6.96 \]
Therefore, the variance of any observation on strength is estimated by \[ \hat{\sigma}_y=\hat{\sigma}^2+\hat{\sigma}_\tau^2=1.90+6.96=8.86 . \] Most of this variability is attributable to differences between looms.
13.2 The Two-Factor Factorial with Random Factors
Two factors \(A\) and \(B\), \(a\) levels of \(A\) and \(b\) levels of \(B\) are randomly selected in the experiment. The model \[\begin{aligned} y_{ijk}&= \mu + \tau_i + \beta_j + (\tau\beta)_{ij} + \epsilon_{ijk}, \end{aligned}\] where \(\tau_i\), \(\beta_j\), \((\tau\beta)_{ij}\), and \(\epsilon_{ijk}\) are random
Assumptions \[ \tau_i \sim \mathcal{N}(0, \sigma_\tau^2),\quad \beta_j\sim \mathcal{N}(0, \sigma_\beta^2),\quad (\tau\beta)_{ij}\sim\mathcal{N}(0, \sigma_{\tau\beta}^2),\quad \epsilon_{ijk} \sim \mathcal{N}(0, \sigma^2) \]
\({V}\left({y}_{{ijk}}\right)=\sigma_\tau^2+\sigma_\beta^2+\sigma_{\tau \beta}^2+\sigma^2\)
Hypotheses of interest \[ \begin{aligned} (a)& \, H_0: \sigma^2_\tau=0 \quad \text{against} \quad H_1: \sigma^2_\tau>0 \\ (b)& \, H_0: \sigma^2_\beta=0\quad \text{against} \quad H_1: \sigma^2_\beta>0 \\ (c)& \, H_0: \sigma^2_{\tau\beta}=0 \quad \text{against} \quad H_1: \sigma^2_{\tau\beta}>0 \end{aligned} \]
The form of the test statistics depend on the expected mean squares
Expected mean squares \[\begin{aligned} E(MS_A)&= \sigma^2 + n\sigma^2_{\tau\beta} + bn\sigma^2_\tau\\ E(MS_{B})&= \sigma^2 + n\sigma^2_{\tau\beta} + an\sigma^2_\beta \\ E(MS_{AB})&= \sigma^2 + n\sigma^2_{\tau\beta} \\ E(MS_{E})&= \sigma^2 \end{aligned}\]
Test statistic for \(H_0: \sigma_{\tau\beta}^2=0\) \[ F_0 = \frac{MS_{AB}}{MS_E}\sim F_{(a-1)(b-1), ab(n-1)} \]
- Expected mean squares \[\begin{aligned} E(MS_A)&= \sigma^2 + n\sigma^2_{\tau\beta} + bn\sigma^2_\tau\\ E(MS_{B})&= \sigma^2 + n\sigma^2_{\tau\beta} + an\sigma^2_\beta \\ E(MS_{AB})&= \sigma^2 + n\sigma^2_{\tau\beta} \\ E(MS_{E})&= \sigma^2 \end{aligned}\]
- Test statistic for \(H_0: \sigma_{\tau}^2=0\) \[ F_0 = \frac{MS_{A}}{MS_{AB}}\sim F_{(a-1),(a-1)(b-1)} \]
- Expected mean squares \[\begin{aligned} E(MS_A)&= \sigma^2 + n\sigma^2_{\tau\beta} + bn\sigma^2_\tau\\ E(MS_{B})&= \sigma^2 + n\sigma^2_{\tau\beta} + an\sigma^2_\beta \\ E(MS_{AB})&= \sigma^2 + n\sigma^2_{\tau\beta} \\ E(MS_{E})&= \sigma^2 \end{aligned}\]
- Test statistic for \(H_0: \sigma_{\beta}^2=0\) \[ F_0 = \frac{MS_{B}}{MS_{AB}}\sim F_{(b-1),(a-1)(b-1)} \]
Notice that these test statistics are not the same as those used if both factors \(A\) and \(B\) are fixed.
The expected mean squares are always used as a guide to test statistic construction.
In many experiments involving random factors, interest centers at least as much on estimating the variance components as on hypothesis testing.
- Estimates of the variance components \[\begin{aligned} \hat\sigma^2 & = MS_E \\ \hat\sigma^2_{\tau\beta} &= \frac{MS_{AB}-MS_E}{n}\\ \hat\sigma^2_{\tau} &= \frac{MS_{A}-MS_E}{bn}\\ \hat\sigma^2_{\beta} &= \frac{MS_{B}-MS_E}{an} \end{aligned}\]
A Measurement Systems Capability Study
A Measurement System Capability Study (also called Gauge R&R study, where R&R stands for Repeatability and Reproducibility) is a key part of quality control and process improvement — especially in manufacturing and lab settings.
Gauge R&R study evaluates how much variation in your measurement data is coming from:
The actual process or product you’re measuring
The measurement system itself (which includes the instrument and the operator)
In short, it tells you: “Can we trust our measurement system?”
Main Goals
- Assess how precise and reliable your measurements are
- Quantify measurement error
- Determine whether your measurement system is suitable for use in a process control or quality monitoring environment
Two Key Components
Repeatability Variation when the same operator measures the same item multiple times using the same instrument.
Reproducibility Variation between operators (or appraisers), i.e., when different people measure the same item using the same instrument.
Basic Experimental Setup
To perform a Gauge R&R study, you typically:
Choose \(n\) parts from the process (covering the process range)
Have \(m\) operators
Each operator measures each part \(r\) times (repeated measures)
(Example 13.1)
A typical gauge R&R experiment is shown in Table 13.1. An instrument or gauge is used to measure a critical dimension on a part.
Twenty parts have been selected from the production process, and three randomly selected operators measure each part twice with this gauge.
The order in which the measurements are made is completely randomized, so this is a two-factor factorial experiment with design factors parts and operators, with 2 replications.
Both parts and operators are random factors. So, we’re more interested in estimating variance components than testing specific factor levels.
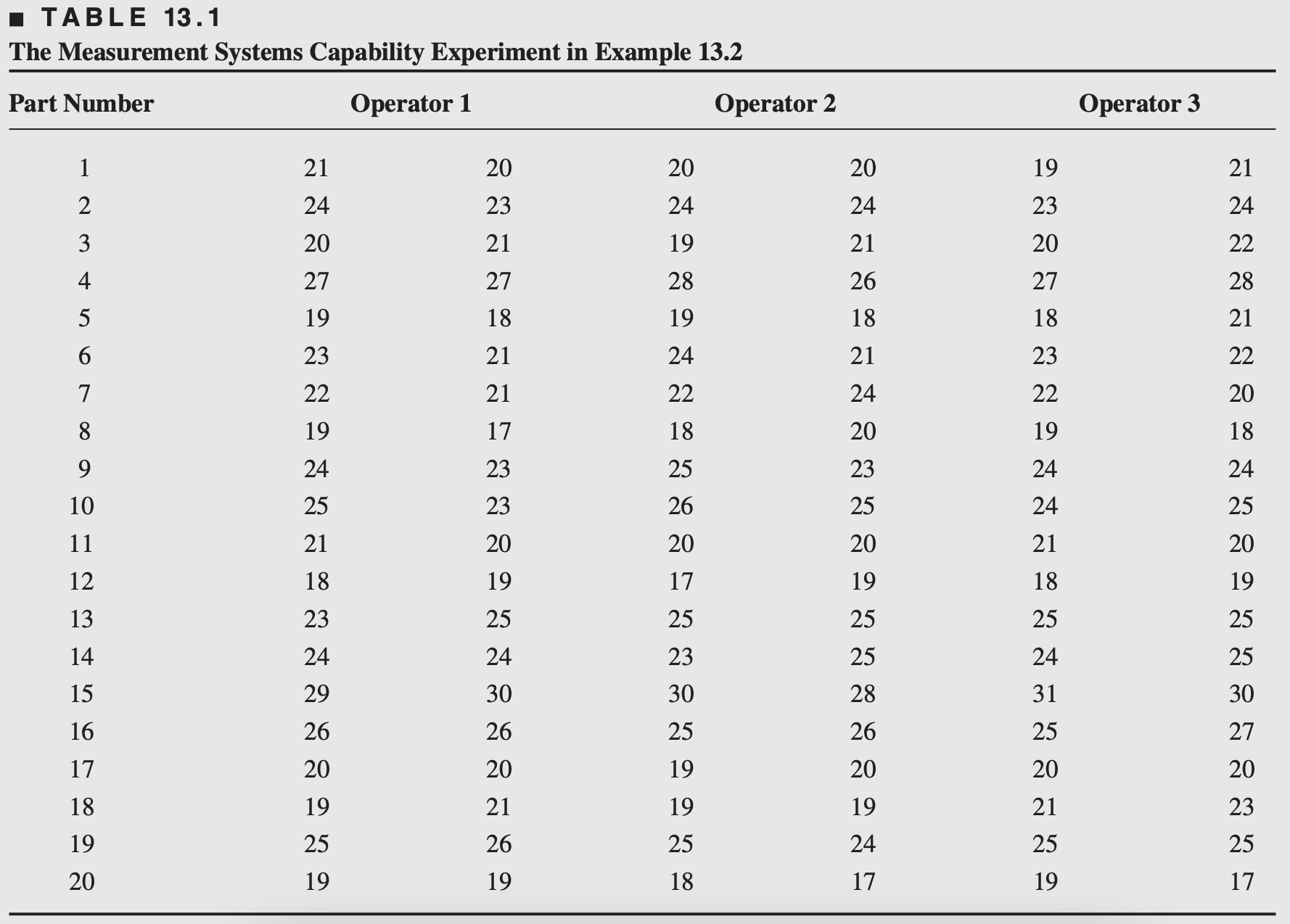
Let: \[ y_{ijk} = \mu + P_i + O_j + (PO)_{ij} + \epsilon_{ijk} \]
Where:
- \(y_{ijk}\): the k-th measurement of part \(i\) by operator \(j\)
- \(\mu\): overall mean
- \(P_i \sim N(0, \sigma_P^2)\): random effect of the i-th part
- \(O_j \sim N(0, \sigma_O^2)\): random effect of the j-th operator
- \((PO)_{ij} \sim N(0, \sigma_{PO}^2)\): interaction between part and operator
- \(\epsilon_{ijk} \sim N(0, \sigma^2)\): repeatability (pure measurement error)
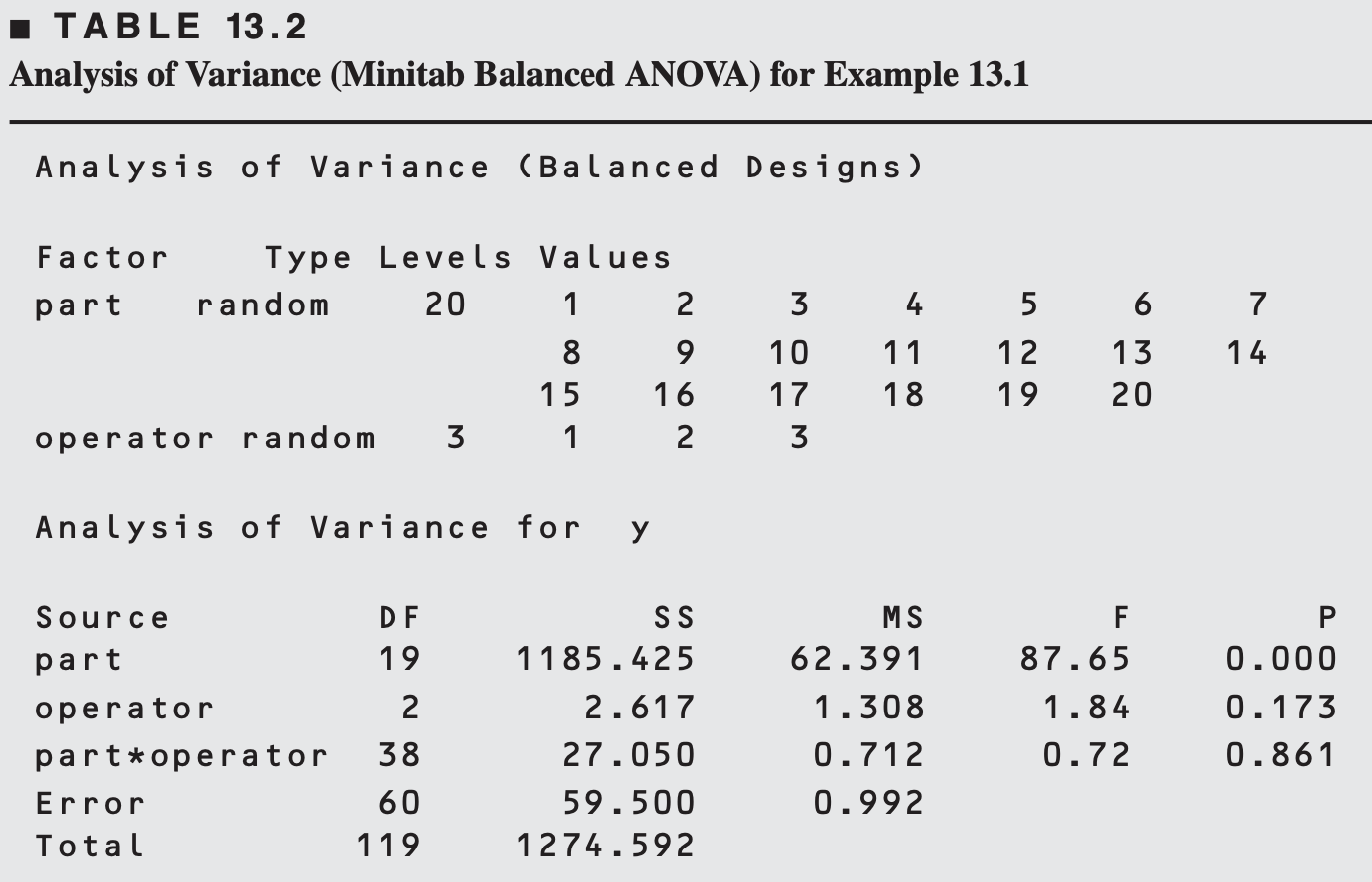
Estimating Variance Components
Using Method of Moments we can estimate:
\[ \begin{aligned} &\hat{\sigma}^2 \quad \text{(repeatability)} = 0.99 \\ &\hat{\sigma}_P^2 \quad \text{(part variation)} = \frac{62.39-0.71}{(3)(2)}=10.28 \\ &\hat{\sigma}_O^2 \quad \text{(operator variation)} = \frac{1.31-0.71}{(20)(2)}=0.015 \\ &\hat{\sigma}_{P O}^2 \quad \text{(part-operator interaction)} = \frac{0.71-0.99}{2}=-0.14 \end{aligned} \]
As interaction is not significant, the reduced model is \(y_{i j k}=\mu + P_i+O_j+\epsilon_{i j k}\)
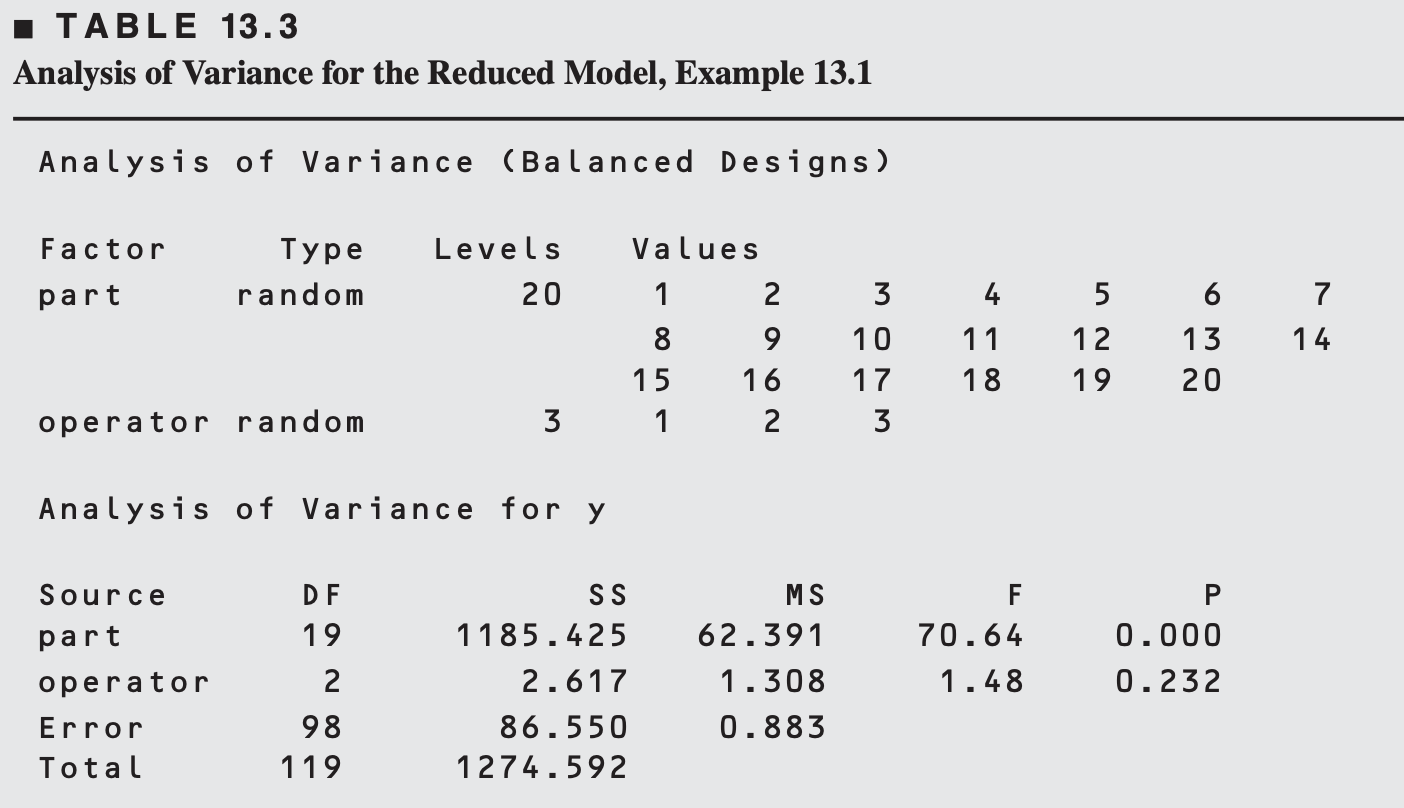
\[ \begin{aligned} & \hat{\sigma}_P^2=\frac{62.39-0.88}{(3)(2)}=10.25 \\ & \hat{\sigma}_O^2 \quad \text{(reproducibility)} =\frac{1.31-0.88}{(20)(2)}=0.0108 \\ & \hat{\sigma}^2 \quad \text{(repeatability)} =0.88 \end{aligned} \]
Finally, we could estimate the variance of the gauge as the sum of the variance component estimates \(\hat{\sigma}^2\) and \(\hat{\sigma}_O^2\) as \[ \begin{aligned} \hat{\sigma}_{\text {gauge }}^2 & =\hat{\sigma}^2+\hat{\sigma}_O^2 \\ & =0.88+0.0108 \\ & =0.8908 \end{aligned} \]
The variability in the gauge appears small relative to the variability in the product.
This is generally a desirable situation, implying that the gauge is capable of distinguishing among different grades of product.
13.3 The Two-Factor Mixed Model
- Suppose the levels of the factor \(A\) are fixed and the levels of factor \(B\) are random
- The two-factor mixed model can be expressed as \[\begin{aligned} y_{ijk} &= \mu + \tau_i + \beta_j + (\tau\beta)_{ij} + \epsilon_{ijk}, \end{aligned}\] where \(\tau_i\) is fixed, and \(\beta_j\), \((\tau\beta)_{ij}\) and \(\epsilon_{ij}\) are random
- Assumptions \[ \beta_j\sim \mathcal{N}(0, \sigma_\beta^2), \quad \epsilon_{ij}\sim\mathcal{N}(0, \sigma^2), \quad (\tau\beta)_{ij}\sim\mathcal{N}(0, \sigma^2_{\tau\beta}(a-1)/a) \]
- Restrictions: \(\sum_i\tau_i=0\), \(\sum_i(\tau\beta)_{ij}=0\)
- This type of mixed model is known as restricted mixed model
- The expected value of the mean squares \[\begin{aligned} E(MS_A)&=\sigma^2 + n\sigma^2_{\tau\beta} + \frac{bn\sum_i\tau_i^2}{a-1}\\ E(MS_B)&=\sigma^2 + an\sigma^2_{\beta} \\ E(MS_{AB})&=\sigma^2 + n\sigma^2_{\tau\beta} \\ E(MS_{E})&=\sigma^2 \end{aligned}\]
- Test statistic for \(H_0: \tau_i=0, \quad \forall \quad i\) \[\begin{aligned} F_0&=\frac{MS_A}{MS_{AB}}\sim F_{a-1, (a-1)(b-1)} \end{aligned}\]
- The expected value of the mean squares \[\begin{aligned} E(MS_A)&=\sigma^2 + n\sigma^2_{\tau\beta} + \frac{bn\sum_i\tau_i^2}{a-1}\\ E(MS_B)&=\sigma^2 + an\sigma^2_{\beta} \\ E(MS_{AB})&=\sigma^2 + n\sigma^2_{\tau\beta} \\ E(MS_{E})&=\sigma^2 \end{aligned}\]
- Test statistic for \(H_0: \sigma^2_\beta=0\) \[\begin{aligned} F_0&=\frac{MS_B}{MS_{E}}\sim F_{b-1, ab(n-1)} \end{aligned}\]
- The expected value of the mean squares \[\begin{aligned} E(MS_A)&=\sigma^2 + n\sigma^2_{\tau\beta} + \frac{bn\sum_i\tau_i^2}{a-1}\\ E(MS_B)&=\sigma^2 + an\sigma^2_{\beta} \\ E(MS_{AB})&=\sigma^2 + n\sigma^2_{\tau\beta} \\ E(MS_{E})&=\sigma^2 \end{aligned}\]
- Test statistic for \(H_0: \sigma^2_{\tau\beta}=0\) \[\begin{aligned} F_0&=\frac{MS_{AB}}{MS_{E}}\sim F_{(a-1)(b-1), ab(n-1)} \end{aligned}\]
In the mixed model, it is possible to estimate the fixed factor effects as before which are shown here: \[ \begin{aligned} & \hat{\mu}=\bar{y}_{\ldots} \\ & \hat{\tau}_i=\bar{y}_{i . .}-\bar{y}_{\ldots} \quad i=1,2, \ldots, a \end{aligned} \] The variance components can be estimated using the analysis of variance method by equating the expected mean squares to their observed values: \[ \begin{aligned} \hat{\sigma}_\beta^2 & =\frac{M S_B-M S_E}{a n} \\ \hat{\sigma}_{\tau \beta}^2 & =\frac{M S_{A B}-M S_E}{n} \\ \hat{\sigma}^2 & =M S_E \end{aligned} \]
- Unrestricted mixed models: no restriction of the random effects terms \[\begin{aligned} y_{ij}&= \mu +\alpha_i + \gamma_j + (\alpha\gamma)_{ij} + \epsilon_{ijk}, \end{aligned}\] where \(\alpha_i\)’s are fixed effects such that \(\sum_i\alpha_i=0\), \(\gamma_j\sim\mathcal{N}(0,\sigma_\gamma^2)\), \((\alpha\gamma)_{ij}\sim\mathcal{N}(0, \sigma_{ij}^2)\), and \(\epsilon_{ij}\sim\mathcal{N}(0,\sigma^2)\).
- The expected mean squares \[\begin{aligned} E(MS_A)&=\sigma^2 + n\sigma^2_{\alpha\gamma} + \frac{bn\sum_i\alpha_i^2}{a-1}\\ E(MS_B)&=\sigma^2 + n\sigma_{\alpha\gamma}^2 +an\sigma^2_{\gamma} \\ E(MS_{AB})&=\sigma^2 + n\sigma^2_{\alpha\gamma} \\ E(MS_{E})&=\sigma^2 \end{aligned}\]
13.4 Rules for Expected Mean Squares
An important part of experimental design problem is conducting the analysis of variance.
This involves determining the sum of squares for each component in the model and number of degrees of freedom associated with each sum of squares.
To construct appropriate test statistics, the expected mean squares must be determined.
By examining the expected mean squares, one may develop the appropriate statistic for testing hypotheses about any model parameter.
The test statistic is a ratio of mean squares that is chosen such that the expected value of the numerator mean square differs from the expected value of the denominator mean square only by the variance component or the fixed factor in which we are interested.
- Rule 1. The error term in the model is \(\epsilon_{i j \ldots m}\), where the subscript \(m\) denotes the replication subscript. For the two-factor model, this rule implies that the error term is \(\epsilon_{i j k}\). The variance component associated with \(\epsilon_{i j \ldots m}\) is \(\sigma^2\).
- Rule 2. In addition to an overall mean \((\mu)\) and an error term \(\epsilon_{i j} \ldots m\), the model contains all the main effects and any interactions that the experimenter assumes exist. If all possible interactions between \(k\) factors exist, then there are \(\left(\begin{array}{l}k \\ 2\end{array}\right)\) two-factor interactions, \(\left(\begin{array}{l}k \\ 3\end{array}\right)\) three-factor interactions, \(\ldots, 1 k\)-factor interaction. If one of the factors in a term appears in parentheses, then there is no interaction between that factor and the other factors in that term.
Rule 3. For each term in the model, divide the subscripts into three classes:
- live - those subscripts that are present in the term and are not in the parenthesis
- dead - those subscripts that are present in the term and are in the parenthesis
- absent - those subscripts that are present in the model but not in that particular term
- live - those subscripts that are present in the term and are not in the parenthesis
E.g. for two-factor fixed effects model, in \((\tau\beta)_{ij}\), \(i\) and \(j\) are live, and \(k\) is absent; in \(\epsilon_{(ij)k}\), \(k\) is live, and \(i\) and \(j\) are dead
(We haven’t seen models with dead subscripts, but we will encounter such models later.)
- Rule 4. Degrees of freedom. The number of degrees of freedom for any term in the model is the product of the number of levels associated with each dead subscript and the number of levels minus 1 with each live subscript.
E.g. the number of degrees of freedom associated with \((\tau\beta)_{ij}\) is \((a-1)(b-1)\), and the number of degrees of freedom associated with \(\epsilon_{(ij)k}\) is \(ab(n-1)\).
The number of degrees of freedom for error is obtained by subtracting the sum of all other degrees of freedom from \(N - 1\), where \(N\) is the total number of observations.
- Rule 5. Each term in the model has either a variance component (random effect) or a fixed factor (fixed effect) associated with it.
If the interaction term contain at least one random effect, the entire effect is termed is considered as random
A variance component has Greek letters as subscripts to identify the particular random effect, e.g. \(\sigma_\beta^2\) is the variance component corresponding to random factor \(B\)
A fixed effect always represented by the sum of squares of the model components associated with that factor divided by its degrees of freedom, e.g. \(\sum_i\tau_i^2/(a-1)\) for factor \(A\) when it is fixed
- Rule 6. There is an expected mean square for each model component. The expected mean square for error is \({E}\left({MS}_{{E}}\right)=\sigma^2\).
In case of the restricted model, for every other model term, the expected mean square contains
- \(\sigma^2\) plus
- either the variance component or the fixed effect component for that term, plus
- those components for all other model terms that contain the effect in question and that involve no interactions with other fixed effects.
The coefficient of each variance component or fixed effect is the number of observations at each distinct value of that component.
To illustrate for the case of the two-factor fixed effects model, consider finding the interaction expected mean square, \(E\left(M S_{A B}\right)\).
- The expected mean square will contain only the fixed effect for the \(A B\) interaction (because no other model terms contain \(A B\)) plus \(\sigma^2\), and the fixed effect for \(A B\) will be multiplied by \(n\) because there are \(n\) observations at each distinct value of the interaction component (the \(n\) observations in each cell).
- Thus, the expected mean square for \(A B\) is \[ E\left(M S_{A B}\right)=\sigma^2+\frac{n \sum_{i=1}^a \sum_{j=1}^b(\tau \beta)_{i j}^2}{(a-1)(b-1)} \]
- As another illustration of the two-factor fixed effects model, the expected mean square for the main effect of \(A\) would be \[ E\left(M S_A\right)=\sigma^2+\frac{b n \sum_{i=1}^a \tau_i^2}{(a-1)} \] The multiplier in the numerator is \(b n\) because there are \(b n\) observations at each level of \(A\). The \(A B\) interaction term is not included in the expected mean square because while it does include the effect in question \((A)\), factor \(B\) is a fixed effect.
To illustrate how Rule 6 applies to a model with random effects, consider the two-factor random model. The expected mean square for the \(A B\) interaction would be \[ E\left(M S_{A B}\right)=\sigma^2+n \sigma_{\tau \beta}^2 \] and the expected mean square for the main effect of \(A\) would be \[ E\left(M S_A\right)=\sigma^2+n \sigma_{\tau \beta}^2+b n \sigma_\tau^2 \] Note that the variance component for the \(A B\) interaction term is included because \(A\) is included in \(A B\) and \(B\) is a random effect.
Two factor fixed effects model \[ \begin{gathered} E\left(M S_A\right)=\sigma^2+\frac{b n \sum_{i=1}^a \tau_i^2}{(a-1)} \\ E\left(M S_B\right)=\sigma^2+\frac{a n \sum_{j=1}^b \beta_j^2}{b-1} \\ E\left(M S_{A B}\right)=\sigma^2+\frac{n \sum_{i=1}^a \sum_{j=1}^b(\tau \beta)_{i j}^2}{(a-1)(b-1)} \\ E\left(M S_E\right)=\sigma^2 \end{gathered} \]
Two factor random model \[ \begin{aligned} E\left(M S_A\right) & =\sigma^2+n \sigma_{\tau \beta}^2+b n \sigma_\tau^2 \\ E\left(M S_B\right) & =\sigma^2+n \sigma_{\tau \beta}^2+a n \sigma_\beta^2 \\ E\left(M S_{A B}\right) & =\sigma^2+n \sigma_{\tau \beta}^2 \\ E\left(M S_E\right) & =\sigma^2 \end{aligned} \]
Restricted form of two factor mixed model \[ \begin{aligned} E\left(M S_A\right) & =\sigma^2+n \sigma_{\tau \beta}^2+\frac{b n \sum_{i=1}^a \tau_i^2}{a-1} \\ E\left(M S_B\right) & =\sigma^2+a n \sigma_\beta^2 \\ E\left(M S_{A B}\right) & =\sigma^2+n \sigma_{\tau \beta}^2 \\ E\left(M S_E\right) & =\sigma^2 \end{aligned} \]
Rule 6 can be easily modified to give expected mean squares for the unrestricted form of the mixed model. Simply include the term for the effect in question, plus all the terms that contain this effect as long as there is at least one random factor.
Unrestricted form of two factor mixed model.
\[ \begin{aligned} E\left(M S_A\right) & =\sigma^2+n \sigma_{\tau \beta}^2+\frac{b n \sum_{i=1}^a \tau_i^2}{a-1} \\ E\left(M S_B\right) & =\sigma^2+n \sigma_{\tau \beta}^2+a n \sigma_\beta^2 \\ E\left(M S_{A B}\right) & =\sigma^2+n \sigma_{\tau \beta}^2 \\ E\left(M S_E\right) & =\sigma^2 \end{aligned} \]
13.5 Approximate F-Tests
Consider a three-factor factorial experiment with a levels of factor \(A\), \(b\) levels of factor \(B\), \(c\) levels of factor \(C\), and \(n\) replicates.
First, assume that all the factors are fixed. \[ \begin{aligned} y_{i j k l}= & \mu+\tau_i+\beta_j+\gamma_k+(\tau \beta)_{i j}+(\tau \gamma)_{i k}+(\beta \gamma)_{j k} \\ & +(\tau \beta \gamma)_{i j k}+\epsilon_{i j k l} \quad\left\{\begin{array}{l} i=1,2, \ldots, a \\ j=1,2, \ldots, b \\ k=1,2, \ldots, c \\ l=1,2, \ldots, n \end{array}\right. \end{aligned} \] Then the analysis of this design is given below
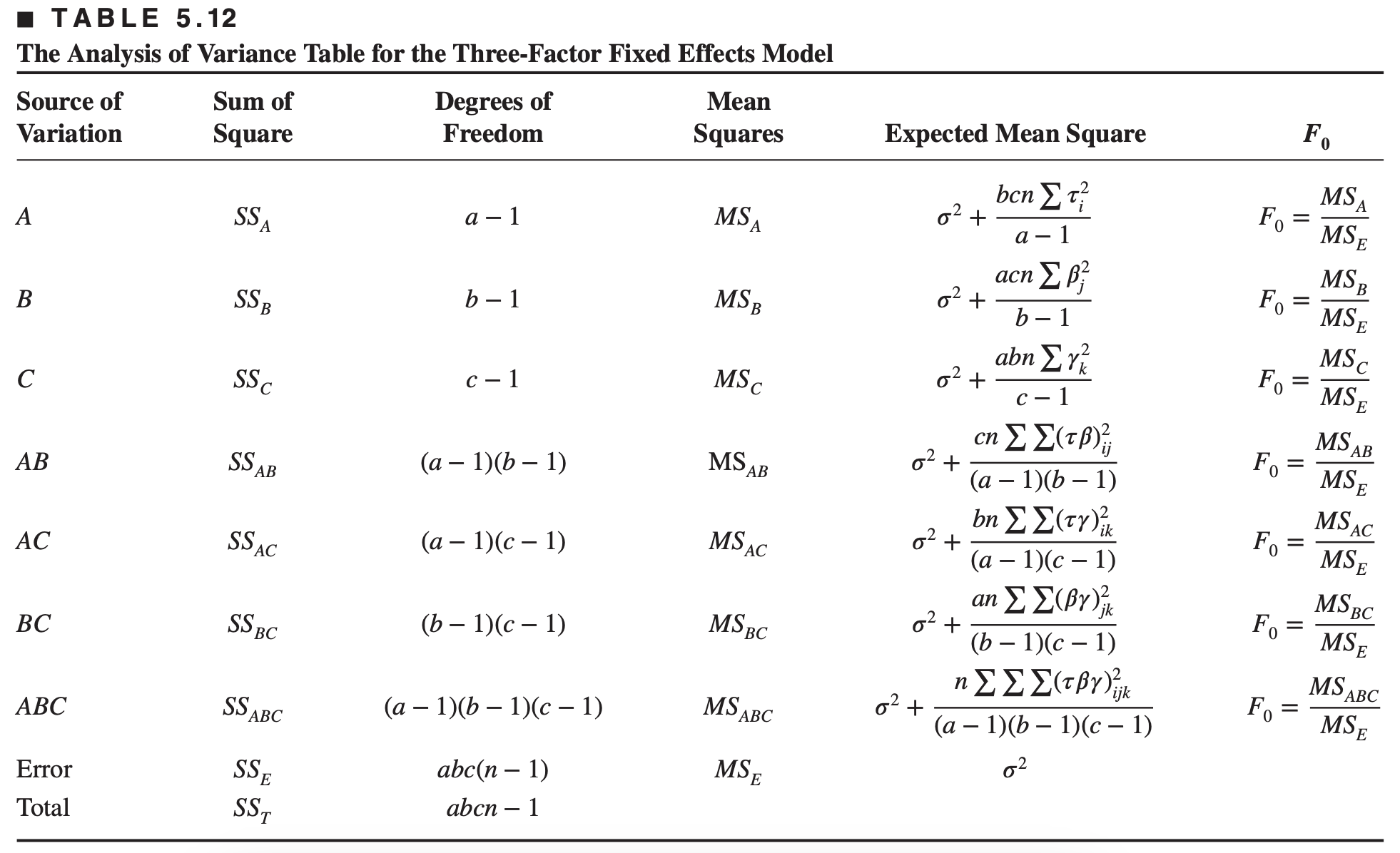
Now, assume that all the three factors are random. The three-factor random effects model is \[\begin{aligned} y_{ijkl} &= \tau_i + \beta_j + \gamma_k + (\tau\beta)_{ij} + (\tau\gamma)_{ik} + (\beta\gamma)_{jk} \\ & \quad \quad \quad + (\tau\beta\gamma)_{ijk} + \epsilon_{ijkl} \end{aligned}\] Assumptions:
- \(\tau_i\sim\mathcal{N}(0, \sigma^2_\tau)\), \(\beta_j\sim\mathcal{N}(0, \sigma^2_\beta)\), \(\gamma_k\sim\mathcal{N}(0, \sigma^2_\gamma)\)
- \((\tau\beta)_{ij}\sim\mathcal{N}(0, \sigma^2_{\tau\beta})\), \((\tau\gamma)_{ik}\sim\mathcal{N}(0, \sigma^2_{\tau\gamma})\), \((\beta\gamma)_{jk}\sim\mathcal{N}(0, \sigma^2_{\beta\gamma})\)
- \((\tau\beta\gamma)_{ijk}\sim\mathcal{N}(0, \sigma^2_{\tau\beta\gamma})\)
- \(\epsilon_{ijk}\sim\mathcal{N}(0, \sigma^2)\)
- All the random effects are pair-wise independent
The expected mean squares assuming that all the factors are random are

- What is the test statistic for \(H_0: \sigma_\tau^2=0\)?
- For three-factor random effects model, no exact test statistic for testing certain effects, e.g. for \(H_0: \sigma_\tau^2=0\) one possible test statistic \[\begin{aligned} F_0 & = \frac{\text{MS}_A}{\text{MS}_{ABC}}\\ &= \frac{\sigma^2 + cn\sigma^2_{\tau\beta} + bn\sigma^2_{\tau\gamma} + n\sigma^2_{\tau\beta\gamma} + bcn\sigma^2_{\tau}}{\sigma^2+n\sigma^2_{\tau\beta\gamma}}, \end{aligned}\] which would be useful if the interactions \(\sigma^2_{\tau\beta}\) and \(\sigma^2_{\tau\gamma}\) are negligible.
If we cannot assume that the certain interactions are negligible and we need to make inferences about those effects for which exact tests do not exist, Satterthwaite’ method can be used.
Satterthwaite’s method uses the linear combinations of mean squares, for example \[ \begin{aligned} & M S^{\prime}=M S_r+\cdots+M S_s \\ & M S^{\prime \prime}=M S_u+\cdots+M S_v \end{aligned} \] are chosen so that \({E}\left({MS}^{\prime}\right)-{E}({MS} \prime \prime)\) is equal to a multiple of the effect (the model parameter or variance component) considered in the null hypothesis.
Then the test statistic would be \[ F=\frac{M S^{\prime}}{M S^{\prime \prime}} \] which is distributed approximately as \(F_{p, q}\), where \[ p=\frac{\left(M S_r+\cdots+M S_s\right)^2}{M S_r^2 / f_r+\cdots+M S_s^2 / f_s} \] \[ q=\frac{\left(M S_u+\cdots+M S_v\right)^2}{M S_u^2 / f_u+\cdots+M S_v^2 / f_v} \] In \(p\) and \(q\), \(f_i\) is the number of degrees of freedom associated with the mean square \({MS}_{i}\)
E.g.
For our example, for testing the null hypothesis, \(H_0: \sigma_\tau^2=0\), we can use the test statistic \[\begin{aligned} F&=\frac{MS_A + MS_{ABC}}{MS_{AB} + MS_{AC}}\\ &=\frac{2\sigma^2 + cn\sigma^2_{\tau\beta}+bn\sigma^2_{\tau\gamma}+2n\sigma^2_{\tau\beta\gamma}+bcn\sigma^2_\tau}{2\sigma^2+2\sigma^2_{\tau\beta\gamma}+bn\sigma^2_{\tau\gamma}+cn\sigma^2_{\tau\beta}} \end{aligned}\]
- Under \(H_0\), the statistic \(F\) follows \(F\)-distribution with \(p\) and \(q\) degrees of freedom, where \[\begin{aligned} p=\frac{(MS_{A} + MS_{ABC})^2}{(MS_A^2/f_A)+(MS_{ABC}^2/f_{ABC})} \\ q=\frac{(MS_{AB} + MS_{AC})^2}{(MS_{AB}^2/f_{AB})+(MS_{AC}^2/f_{AC})} \end{aligned}\] and \(f_{A}\) is degrees of freedom associated with \(MS_A\).